
视觉语言变换是多态学领域的重要研究课题。它可以同时编码图像数据和语言数据.两个是排列在嵌入空间执行下游任务。但目前的视觉语言转换器工作仍需要对ImageNet的视觉骨干进行预训练,然后使用关键视觉目标的注释框指导,可完成功能映射的视觉目标和语言描述,该模型主要依靠预训练的数据集和注释。模型的学习能力和可扩展性受到严重限制。本文首先讨论了上述模型的缺点,它还介绍了目前更先进的自监控的 Masked Auto-Encoders(MAE)技术,一种视觉语言转换模型(从captions中获取的视觉语言,VLC),VLC对一系列下游任务(包括视觉问答VQA,自然语言和视觉推理NLVR和图像文本检索任务都表现出较好的性能。本文来自卡内基梅隆大学和微软研究所.

参考文献: https://arxiv.org/abs/2205.09256 代码链接: https://github.VLC/guilk一、引言
用于视觉语言共建,大体上有两种模式,首先是使用视觉特征来引导语言特征,第二种则与此相反,即首先编码语言数据,然后使用语言信息来构造视觉表示。现有的视觉语言Transformer主要遵循后者,把语言特征放在第一位,而对于视觉部分,部署在ImageNet上预先训练的可视字符提取器,并使用 bounding box 和 ROI 操作提取有趣的视觉特征.
在这种模式下,视觉特征被迫被嵌入在大规模材料中预先训练的语言空间中。视觉转换器(ViT)的出现[2],这个固定的范式已经发生了变化,例如,基于ViT的ViLT[3]模型,首先, 用视觉概念初始化模型.并将语言嵌入相应的视觉补丁的映射中,这大大提高了模型的理解性,同时,这个新模型也有一些工程优势,因为它消除了从前方法导出的ROI计算成本。
但这一模式也有其缺点。由于ViT通过监控的视觉标签进行训练,结果的表示可能受到像ImageNet这样的数据集的语义边界限制,为了解决这一问题,作者团队巧妙地介绍了 Masked Auto-Encoders(MAE)技术,以协助模型进行自我监控培训,它还增强了模型对其他不熟悉的视觉或语言概念的一般化能力。下面的图显示了该方法的可视化,与以前的监控模型方法(ViLT)相比,視化字是動詞「推」。你可以看到,这种方法可以非常准确地定位于投球运动者和投球运动员。ViLT的定位效果很差。

二、本文方法
该方法的设计目标是完成有效的视觉语言变换模型的构建,并无监督预培训。该模型是基于视觉ViT框架构建的。该模型可分为两个阶段。
首先,通过图像编码/语言嵌入对多模式的自我监督重建进行研究;
然后,在前面步骤中获得的多模式特性将在图像和文本匹配模式之间排列。
为了完成上述两个步骤,作者为VLC框架设计了三个模块,下面的图表显示了VLC框架的整体架构,它由一个特定模型映射模块、一个多模型编码器和一个有三个特定任务的解码器组成,红色和蓝色的箭头分别代表图像和文本的信息流,在模型特定的映射模块中,作者使用简单的线性投影来编码图像块,并设置一个词嵌入层以编码输入文本.在多模态编码器中,作者使用MAE自监督预训练的12层ViT(使用ImageNet-1K)作为编码器的主要驱动器。在特定任务的解码器模块中,作者设置了三个预培训任务,下面进行详细介绍。
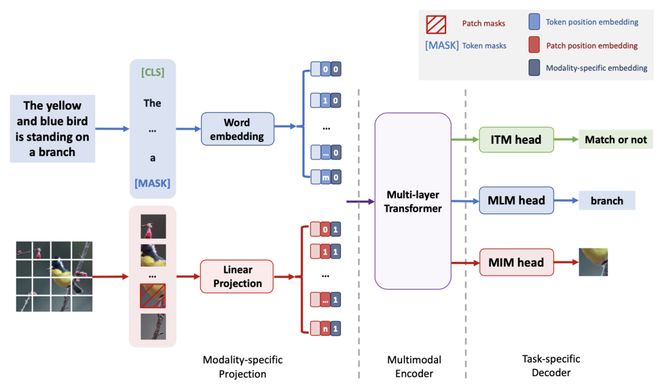
2.1模型特有映射模块
以前,处理原始数据的编码问题时,最初的视觉特征仍然通过使用一个非常复杂的CNN特征提取器和目标检测框架中的一些对象检测组件来获得。这在一定程度上增加了模型的复杂性,本文采用一种可训练的线性投影层来代替它.直接转换图像块到可视嵌入空间, ,其中图像块数目,视觉嵌入的特性维度.对于词嵌入层,作者仿真了BERT[4]来标记输入句子,然后,通过 word embedded 搜索层, 标记词矢量被投影到文本嵌入空间中.得到 ,其中有牌子的数目,随后,嵌入位置由嵌入位置和嵌入位置编码。还有两个嵌入的标记,最后的嵌入式计算公式如下:
2.2多模式编码器
多模式编码器的作用是将输入的视觉和文本嵌入向量在各模式之间同步。输出具有更稳定的多型特性,本文根据单流方法的设置,使用ViT-B/16结构作为多模式编码器,它包含12个不同的多头注意力层(MSA)和MLP层。
为了同步这两个模式,作者利用结合注意力机制[5]来结合视觉和文本模式,具体操作为,首先是视觉和文本嵌入嵌入在一起,以取得结合嵌入,随后发送到变换器层获取上下文排列表示,与其他双流方法相比,这种设计可以提高模型参数效率,此外,由于编码器通过MAE进行自我监督和预备训练,对报价数据的需求也减少了。
2.3 特定任务调解器
为了获得下项任务所需的文本的视觉和一般表示,本文对上述两步多模特性进行自我监测预训练。与以前只掩饰文本符号的方法不同,这里作者同时掩盖图像块和文本符号,设计了三个独立的自我监控任务:(1)Masked Language Modeling,MLM),(二)Masked Image Modeling,MIM),(三)图像-文本匹配,ITM)。
Masked Language Modeling
在语言模式的预训练中,MLM随机封锁输入文本符号,训练模型根据上下文再构造盾牌区域,作者详细地模拟了BERT模型,让我们从0.probability random blocking token开始,在模型特定的映射模块中,将一个特殊的标记放在面具符号上,其目的是基于文本和图像块来预测块。MLM头由线性层组成,与词汇相关的日志的直接输出,方便计算与文本相似损失的块面积负数对,MLM目标函数可以表示为:
Masked Image Modeling
对于视觉预训练,本文遵循原先的 MAE 方法,输入图像会随机屏蔽60%的区域,然后根据和直接恢复原始图像块像素,MIM头由8层变压器组成,对每个被丢弃的图像块,重组损失可以表现为:MIM的总体目标功能可以表现为:
Image-Text Matching
除了上述的日常语言和视觉模式预训练任务外,作者还介绍了模式间匹配的匹配任务ITM,具体来说,分配了一系列图像和文本数据对,ITM头需要确定输入序列是否整齐。作者将有50%的可能扰乱两个相连的序列。这两个模式被合并,特征被输入到ITM头部进行训练。ITM头也通过一个简单的线性层实现,目标函数可以表示为:
显示当前图像和文本序列是否匹配.
三、实验效果
本文的实验设置主要分为两个步骤,首先,对大规模的视觉和文本数据集进行预训练,然后将预训练模型扩展到较低的任务,该 模型 的 业绩 评价 主要 反映 于 下游 任务 的 影响 。预培训库包含四个常见的视觉语言数据集。包括 COCO 、 Visual Genome 、 Google Conceptual Captions 和 SBU Captions,总共有4亿幅图像和510亿幅图像-文本对,在完成预训练之后,本文主要对VLC在三个多模式下游任务中进行评价.三个任务是图像文本检索、视觉查询VQA和自然语言和视觉推导NLVR。
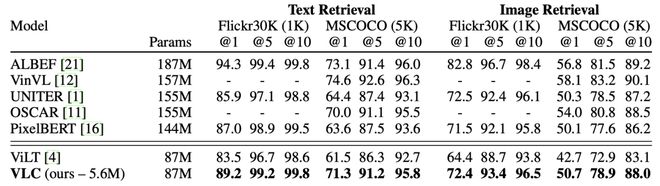
图像文本检索包含两个子任务:图像到文本检索(TR)和文本到图像检索(IR),作者对两个权威的基准MSCOCO和 Flickr 30K进行了比较实验。实验结果见下表。在某些方法中,快速的RCNN检测器被集成到MSCOCO中,这是事先训练的。它有更好的 ROI利用,拟议的VLC框架放弃了这些结构。通过麦克风ITM头直接执行检索任务,相反, 他们表现得更好.
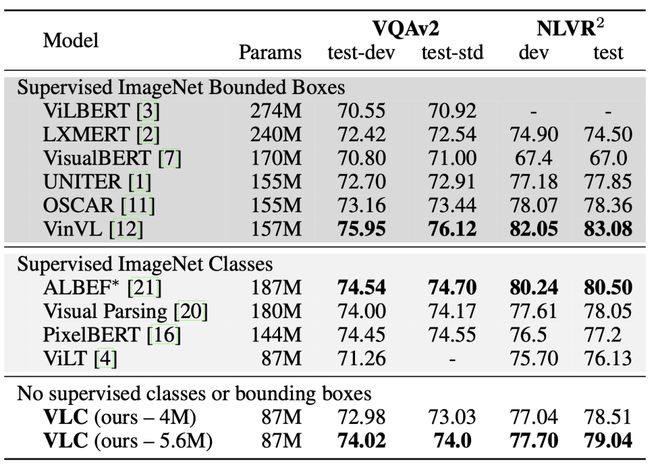
与图像文本检索任务相比,VQA和NLVR任务更反映了模型在多模式嵌入空间中推导的能力,下表显示了VLC框架在这两个任务中的结果,作者对两种监督培训方法进行了对比.第一个方法是仅提供目标来监督ImageNet的回归框架,另一个是在ImageNet上只提供目标类信息,以供监督,作者还提供了两个版本的VLC方法,你可以看到当参数为4M时,VLC的性能与监控方法有很大的不同.但当参数数量增加到5.在6M时,VLC的性能已经超过了一些监督方法,这验证了VLC的可扩展性和基于MAE的自监测任务的有效性。
为了更好地理解VLC的工作模型,作者还做了一种可视化分析,需要明确的一点是,VLC使用图像块作为视觉文本匹配的基本单元。前一种方法是首先根据边框重新定位图像上的特征。这两个过程完全相反,作者列出了一个简单的图像块聚类的可视化例子,如下图所示,ViLT和VLC的图像补丁嵌入分别被分组(彩色)。ViLT的图像块大小相对较大,VLC的图像块分辨率更好,可以看到,VLC能够更准确地识别图像中的关键语义区域,例如, 地毯 、 墙壁画 、 橱柜上的植物等.它可以被看作是一个从下到上匹配的过程。

四、 总结
本文提出了一种新的视觉语言任务预训练模型。与以前的预训练目标检测器和监督训练的CNN/ViT模型相比,本文提出的VLP模型,仅用少数简单的线性层对预训练进行自我监控,可以对多个下游任务产生良好的效果。大型预培训库和多样化下游任务适应也验证了VLC框架的扩充能力。此外,VLC视觉可以准确地将图像块与文本数据匹配,这表明了更强的可理解性能。作者希望,拟议的VLC将为社区进一步研究大规模弱监管的开放区域视觉和语言模型铺平新的道路。
参考文献
[1] He, K., X. Chen, S. Xie, et al. Masked autoencoders are scalable vision learners. CVPR, 2022.
[2] Dosovitskiy, A., L. Beyer, A. Kolesnikov, et al. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021.
[3] Kim, W., B. Son, I. Kim. Vilt: Vision-and-language transformer without convolution or region supervision. In ICML. 2021.
[4] Devlin, J., M.-W. Chang, K. Lee, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. NAACL, 2019.
[5] Dou, Z.-Y., Y. Xu, Z. Gan, et al. An empirical study of training end-to-end vision-and-language transformers. CVPR, 2022.
作者: seve n_
Illustration b y Alex Manokhi from icon s8
-The End-
7.6星期三 19:00
请来现场预订或办理登记手续!

扫码观看!
本周上新!
关于我“门”
郑门是新成立的创业投资公司,致力于探索、加速和投资技术驱动的创业企业,包括郑门创新服务、郑门技术社区和郑门投资基金。
該公司於2015年底成立,由Microsoft的中國創始人創立,他為Microsoft選擇了126家創新科技企業,並 deeply養育了他們。
如果您是技术领域的先驱,并不仅想获得投资,而且想获得一系列可持续和有价值的投资后服务,欢迎向我发送或推荐项目:
bp@thejiangmen.com

点击右上角分享文章与朋友
让你到达 TechBeat的快乐星球的钥匙