
作者:钟娟 ,复睿微电子自动驾驶算法专家,毕业于中国科学院,曾就职于清华大学联合研究所,先后担任资深算法专家、系统架构专家,长期从事图像算法和人工智能领域科学研究工作。
据台湾的联合和环球报导,7月22日上午,台湾艺术家林英开车时发生了交通意外.引起了网友关注。事故发生在台湾莫莫源市中北部公路上,当时林英在交汇处驾驶了一辆Tesla Model X,终于下车了。之后,车辆通常在三条车道中间行驶,在接近分支点时,突然离开道路,出于不明原因,在公路中与一个单独的岛屿发生碰撞,导致一辆汽车燃烧。所幸事故发生时,附近工作地点的工人第一次急忙抢救,把林的父亲带出来,把他送到一个安全的地方,避免更严重的伤亡,但林在许多地方受伤并骨折。他被送往梁口长光医院接受治疗.
从现场视频来看,路面条件、 visibility及碰撞区天气良好,由于刚完成掉头,车速看起来也不快。有人对视频做了详细的分析,那辆车离碰撞的直线大约是180米,行驶总用时12秒,平均速度为55公里/小时,最初的10秒是在中间的车道上。最后两个秒钟,我们开始远离道路,它以每小时60公里的速度坠入孤岛。据救援人员描述,当林被救出时,安全带被断开。但是事故前解开还是事故后解开并未得到证实。
事故原因仍在调查中,那辆撞车的一半被烧毁了,林目前已知,由于大脑撞击, 一些事故的记忆都丢失了.该事件可能只在需要等待林完全恢复之后才充分呈现出来。关于事故原因分析的猜测主要有两个类别:
1
有些人认为这是车辆系统的问题,当辅助驾驶被激活时,泰斯拉汽车驾驶员很可能不会认出前向V形输送带和驾驶门,导致碰撞。2018年3月发生了类似事件,这款X型车由苹果工程师黄伟伦驾驶,当自动pilot启动时,与美国加利福尼亚州公路的边界栅栏相撞,导致车辆起火,不幸遇难。
2
有些人认为这是由人类引起的,因为林被救的时候,他的安全带被断开,泰斯拉拆卸安全带将迫使自动辅助驾驶的退出,车辆交给人控制,根据林的赛车驾驶经验,离公路2秒应该足够时间,以避免人工干预,但从车辆的轨迹中可以看出,没有办法阻止运动发生,极有可能是分神了。
这次事故的X型号配备了L2级自动pilot,L2级自驾驶是通过驾驶环境向转向轮提供驾驶支持和加速中的许多操作,司机必须在整个行程中,密切关注和实时观察周围环境,随时准备接管车子。L2阶段,目标和事件检测和响应任务由司机和系统共同承担,司机和自驾驶系统之间的责任尚不清楚,或者司机对自己驾驶的过度自信,这是L2级自驾车事故的潜在原因。目前,大多数L2级的车辆要么是纯粹的,要么是视觉 oriented.雷达为辅,每个传感器都执行识别任务,然后进行基于重量的重合。如果发现视觉障碍,不管雷达发现什么,车辆都会做出反应,反过来就不行。那些尚未被看见的物体在眼前都有一个盲点.只有长期积累相关数据才能逐步提高模型的鲁棒性。但新事物, 如奇怪的汽车座位, 也会导致视觉误解.因此,未来型号的自动试验计划中,许多人使用雷达和视觉的结合来感知.
现在,我国的许多车辆处于L2+阶段,向L3/L4级的过渡面临巨大的挑战。除了硬件的升级,各种基于硬件的进化算法不断提出.Transformer在这一轮的算法迭代中被深入研究,基于纯视觉的Tesla的变换器有效地将多个相机的特点集成到BEV空间中。它也吸引了广泛的注意Transformer。近期,我们对Transformer模型进行了深度剖析,应用场景、算法原理、操作者和硬件加速模型进行了多维思考。
变形原理
Transformer是由Google提出用来进行机器翻译的神经网络模型,第一个问题是在自然语言处理中很难同时计算的RNN(循环神经网络)。想找到类似CNN(容量神经网络)的网络实现并行处理。
Transformer使用Attention机制,Attention机制中的Q、K、V对应Query、Key、Value,查询 、 键和值的概念是从信息检索系统中提取出来的.举例来说,当你在零售平台搜索产品时,引擎上的输入是查询,然后根据查询,搜索引擎将与键(产品属性)匹配,然后根据查询和键的相似性确定相应的内容值。
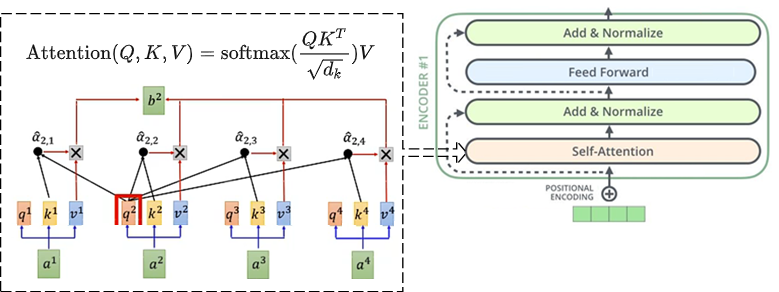
Self-Attention中的Q,K,V也扮演了类似的角色。在矩阵计算中,点积是计算两个矩阵相似性的方法之一。使用Q和K来计算相似性,然后, 根据相似性, 与V进行权重匹配.正确的值是查询和键的相似性。经过Self-Attention层后,输入信息建立彼此之间的联系,这种连接可以通过平行计算(矩阵操作)完成。但是这个矩阵计算了未知的位置信息(没有序列),因此,Transformer对输入进行了位置编码(Positional Encoding),输入的序列位置和顺序信息被一起送入网络,存储输入图像的位置信息和音频的时间信息。Self-Attention的输出会再经过归一化和前馈网络,完成一个编码层的工作,在Transformer中, 多个编码层被层化完成编码工作.建立输入信息之间更紧密的联系.
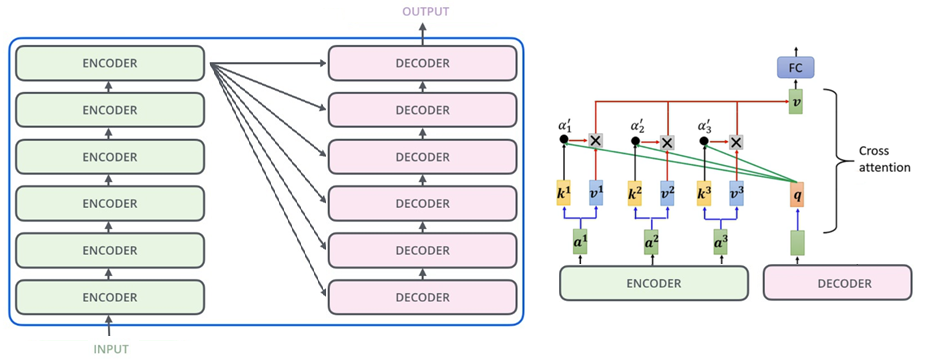
Transformer的解码器也包含多个Decoder Layer, Decoder Layer和Encoder Layer在机构上非常相似,最大的区别是,Decoder Layer采用Cross-Attention机制,也就是说,查询来自Decoder,Key和Value来自于Encoder。编码器的输出维度与原始信号维度一致,调试器的输出大小可以根据不同的要求定制,它与原始信号大小无关。例如,当汽车图像处理完成时,编码器输出是图像字符金字塔层(240x135x256)的输入大小,Decoder输出可以是定制的鸟眼视图(BEV视图)特征尺寸(100x100x256),或定制的检测帧(100x3x256)。这也是Transformer的神奇之处,网络将对象从一个特征空间转换为另一个特征空间.你不必考虑如何匹配两个空间,变换器会自动为你做。
Transformer模型在视觉领域发展历程
基于Transformer的BERT算法在NLP的11个任务中取得了显著的改进。2018年深入学习领域最令人兴奋的消息,2020年,Google团队提议将Transformer应用于图像分类。有些人认为CNN是一个变换器的子集,变换器可以产生全球注意力的图像,而CNN则是周边图像的局部关注,Transformer的全局关注包含了CNN局部关注的特殊情况(把除周边像素外的关注权重都设成0)。Transformer在图像领域主要有如下几个关键模型:
1
ViT,ViT将图像分割成多个补丁(16x16块),因此,一个向量序列(256个向量)被组合起来。将图像的二维结构转换为一维,输入到Transformer网络中进行编解码,完成图像分类任务。可以通过完全使用变换器来获得结果。
2
DETR,DETR首先通过CNN提取图像的特征,然后每个特征图的像素(通道方向)被用作向量,HxW是一个序列向量,从而将图像的二维结构转换为一维,输入到Transformer网络中进行编解码,完成目标检测任务。DETR使用CNN和Transformer的组合,它是第一台全端至全端目标检测器。因为它的注意力机制是像素水平,计算量非常大,在实际应用中不可接受的计算复杂性.
3
Swin-Transformer,Swin-Transformer提出了一种基于窗口的注意力计算方法,限制本地窗口中的像素之间的注意机制,用一个类似CNN的层状结构,每层开不同的窗,加强像素之间的连接。Swin-Transformer的结构,这使得它可以替换CNN作为视觉任务的主要网络,以提取图像特征。
4
Deformable DETR,Deformable DETR采用Deformable Attention(变形注意力机制),该模块的概念起源于Deformable CNN。变形DETR遵循DETR的概念,不同的是仅从特征图中Query的邻域内预测固定数量(4个)的采样点计算Attention,从模型训练中了解了邻近采样点位置的极化问题。由于使用稀疏的注意力模式,计算量大幅度下降。其Deformable Attention的机制能够让模型自动学习到感兴趣的区域(像素点)来进行关注,该机制在BEV特征融合、特征金字塔多层融合和多传感器特征融合中广泛应用。
变换器在自动pilot算法的演化中的应用
变形器在自主驾驶中的应用已成为一种趋势,除了广泛应用于基于BEV特性的预融合中,变换器还可替换CNN和RNN实现图像字符提取、金字塔字符融合和时间序列字符提取应用。近年来,国内外基于变换器的主要研究内容如下:
1
BEVSegFormer,在Resnet提取功能图后,采用类似于Deformable DETR的结构对每个相机多尺度特征进行编码,然后对BEV特征空间中的多摄像头特性进行了解码,得到了BEV视觉特征。然后输出BEV语义分割结果.
2
BEVFormer,在Resnet提取功能图后,同样采用类似于Deformable DETR的结构。先利用Temporal Self-Attention对前一时间戳进行查询,将历史时刻的信息融入其中,然后使用 Space Cross-Attention在BEV功能空间中投影多个摄像机,融合多相机信息,得到BEV特征,然后用相应的头进行3D目标检测和语义分割.
3
DETR3D,从Resnet提取功能,然后使用FPN融合功能金字塔,获得多层金字塔特征后,输入到Deformable DETR的解码器中。与BEVFormer和BEVSegFormer不同,DETR3D的编码器输入和输出不是BEV的特性图,而是BEV视角下包含9个维度(位置3、大小3、航向角2、速度1)的检测框Object Queries。DETR3D的解码器Self-Attention模块将Object Query进行全局交互避免多个Query收敛到同个物体,同时,将每个对象查询的边界帧中心发送到一个子网,对多个相机的多层金字塔特征进行具体的投影计算,并取得投影特征。然后将投影特征和Self-Attention层的输出做Cross-Attention,更新对象查询的检测框和类别。
4
FUTR3D,FUTR3D具有与DETR3D相似的结构,不同之处在于FUTR 3D集成了多传感器信息的摄像机、激光雷达和毫米波雷达。使用resnet来提取摄像机的功能,用PointPilar对激光雷达的特性进行了提取,米波雷达直接使用雷达点云.在特征投影时,雷达直接从BEV下的三维参考点射出,摄像机使用了像DETR3D一样的投影,然后将所有传感器投影特性分类,最后,利用MLP网络编码集成投影特性,编码器结构类似于DETR3D,输出还包括3D检测框和类别。
5
MUTR3D,MUTR3D是一个端到端目标跟踪框架。这些功能分别由Resnet和FPN提取,并结合了多维功能。然后,MUTR3D对每个帧执行两个类型的查询,新的查询在3D检测框对象查询中得到,类似于DETR3D,旧查询Old Query是来自先前帧成功检测或跟踪到的目标。旧查询负责在当前帧中跟踪先前发生的目标(第一个成功检测被分配),新查询负责检测当前帧中新出现的目标(与旧查询不相符的对象),两个查询一起完成跟踪任务。MUTR3D采用与DETR3D相似的变换器结构,3D目标检测跟踪可以完成。
此外,VectorMapNet使用Transformer用于高精确的end-to-end映射学习;BEVerse和BEVDet使用SwinTransformer用于多摄像机特征提取;PETR是DETR3D的一个改进,将摄像机图像投影到3D锥体空间后,3D目标检测和分类方法与DETR3D相似。此外,PETR还使用Swin变换器进行文字提取。
硬件加速中的变压器的需要
从最近的算法进化应用中可以看出,在自动驾驶领域用得较多的Transformer模型主要集中在用Swin Transformer做图像特征提取以及用Deformable Attention做多尺度、多相机、多传感器的特征融合。对两种模型的算法结构进行了分解.与CNN网络相比,可以得到下列硬件加速度变化:
1
矩阵运算(Matrix Multiply)
2
大量1x1卷的计算,主要是在CNN网络中的3x3卷。
3
位置编码的罪/费用计算
4
Swin Transformer中各层中不同window对于数据tile的影响以及片内存储的需求
5
Deformable Attention机制中,多采样点的位置偏移量对数据tile和片内存储的需求
6
大模型(量化前的Transformer模型动作几百M,甚至上G)在加速单元里的部署
Transformer在GPU上已经实现了落地,但功耗较高。为了获得更低的功耗,我们进行了新的NPU架构设计来同时满足CNN和Transformer模块的加速。
参考文献:
End-to-End Object Detection with Transformers
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
An image is worth 16x16 words: Transformers for image recognition at scale
DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO -END OBJECT DETECTION
BEVSegFormer: Bird’s Eye View Semantic Segmentation From Arbitrary Camera Rigs
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
FUTR3D: A Unified Sensor Fusion Framework for 3D Detection
MUTR3D: A Multi-camera Tracking Framework via 3D-to-2D Queries
BEVerse: Unified Perception and Prediction in Birds-Eye-View for Vision-Centric Autonomous Driving
VectorMapNet: End-to-end Vectorized HD Map Learning
BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
PETR: Position Embedding Transformation for Multi-View 3D Object Detection
公司简介
复睿微电子是世界500强企业复星集团出资设立的先进科技型企业。先进的微电子技术根源于创新文化,通过技术创新,改变人们的生活、工作、学习和娱乐方式。公司成立于2022年1月,目标是成为智能旅行时代全球领先的大规模计算解决方案供应商。我们致力于在汽车电子、人工智能和通用计算领域提供高性能芯片解决方案。
目前主要从事汽车智能驾驶舱、ADS/ADS芯片开发,具有领先的芯片设计能力和人工智能算法,通过底层技术赋能,促进汽车工业的创新发展,提高人们旅行的经验。在智能出行的时代,芯片是汽车的大脑。复杂智能旅游集团已经构建了一个完美的智能旅游生态,更新微机是整个生态系统通用和人工智能计算的基础平台。我们致力于改善客户体验,通过先进的封装、先进的编程和解决方案,在摩尔的法律时代不断增强了计算能力。与我们的合作伙伴一道,面对着智能汽车的新时代。