

新智元报道
编辑:LRS 好困
在我看来,人类不再比大赦国际更了解。 最近,在Toshio镇,微软清华姚班毕业生开发了一个新的系统,KEAR,它成功地将一些常识问答列入清单,这是第一次比人类好,即使它不是英语。
AI模式总是有缺陷, 因为它只能是“死学习 ”, 只能根据特定培训样本预测, 无法回答任何“常识”询问。
就像你说的 GPT -3 -3 太阳有多少只眼睛?
它不会害羞地告诉你:"当然,这是眼睛!"

由于所提交的语言中没有常识信息,如果没有常识,唯一的解决办法是驴嘴唇不是马的嘴。
为解决这种常识问题,研究人员利用概念网来建立常识QA,这是一个常识专用数据集,需要模型来理解常识,以便成功解答问题。
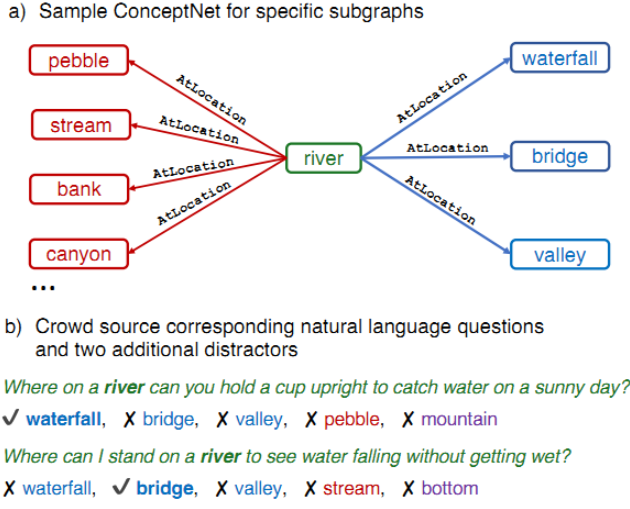
每个问题都有五个可能的答复,其中两个是非敏感的答复,使大赦国际模式的工作更具挑战性。
我不知道我在说什么 你的狗会喜欢什么问题?
萨拉德,被抚摸, 爱,骨头, 大量的注意力,等等 可能是答案。说到跟狗约会很明显,大多数狗都喜欢吃骨头原来你的狗和候选人一样 更喜欢骨头但AI模型并不懂。
为了准确回答这个问题,有必要了解如何应用外部知识。
共同enseQA的创建者随后测试了Bert-Large模型,该模型当时贯穿了主要排名,准确率仅为55%.9%,而人类回答率为88.9%。
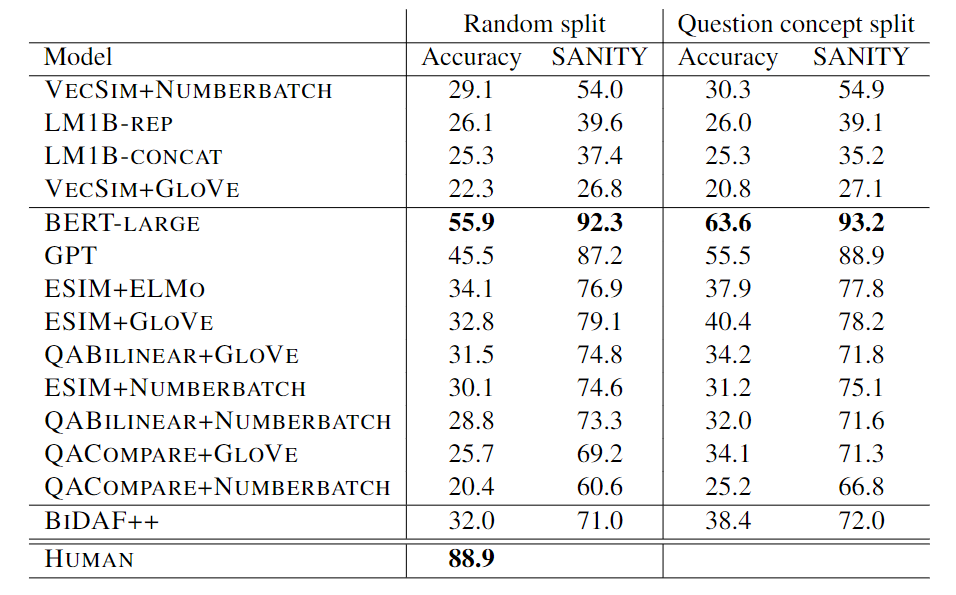
时间来到三年后,微软的中国团队最近制作了一份关于中国形势的研究报告。该国实施了知识外关注共同理由制度。常识质询质量协会达到了新的常识问答表现水平。准确率为89.4%。成功超越人类,这是人工智能常识领域的一个开创性模型。

与典型的AI模型相比,培训需要大规模数据,项目的结果尚无法获取。研究表明,采用外部关注技术来改进作为互联网发展工具的变换器结构。在将外部知识信息纳入预测的过程中,有可能产生差异。这最大限度地减少了对大模型参数的要求。这是人造情报系统第一次变得更加民主。换句话说,我们可以减少AI型模特的酒吧数量。我们不需要从王那里买很多牌SOTA业绩也是一种可能性。
大体来说,当Kear模型被问道, “你的狗喜欢吃什么?”它最初获得概念网络有形链条的"狗" -"污物" - -"刮伤,操作,骨,"注意"它排除了不正确的沙拉反应。
然后从Wiktionary取回骨头的定义:构成大多数动物骨骼的复合物;
狗喜欢吃什么?
KEAR使用获得的知识和输入的知识,作为Deberta模式的投入,从而得出正确的答案:Bones!

可以看出,AI模式需要相当数量的外部知识才能回答人类最简单的询问。
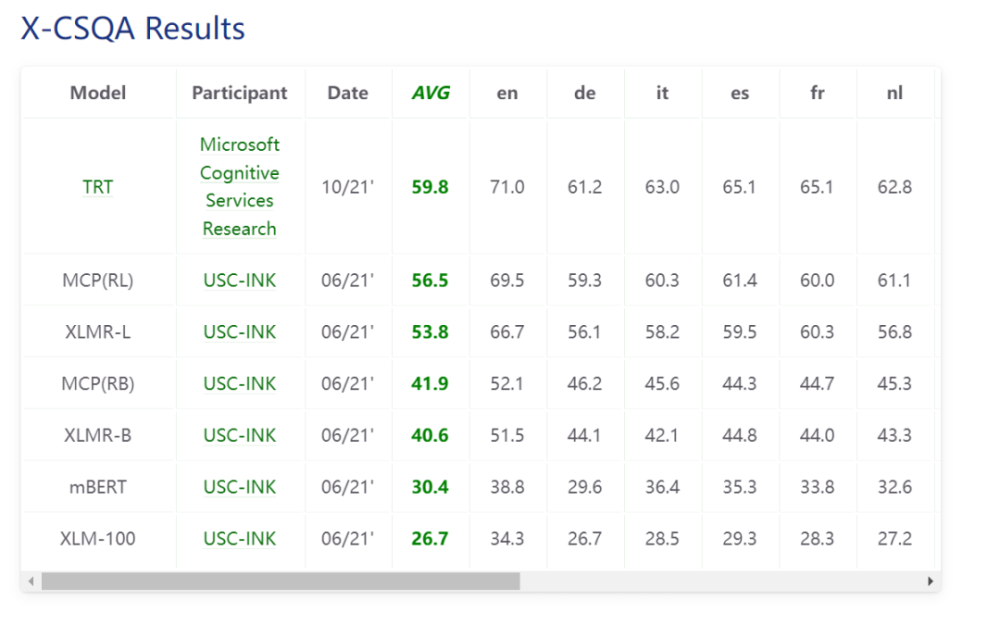
虽然常识QA只是一套关于英语常识的问答数据,但它也调查其他语言的常识推理是否仍然可行。
研究人员首先将非英语问题翻译成英语,然后从英语材料数据中恢复信息,将知识文本翻译成原语言,然后在外部关注程序(即翻译翻译翻译翻译)之后翻译答复。
因此,X-CODAH和X-CSQA这两个特派团首先采用X-CSR基准。
不止于自注意力
迄今为止,大多数大赦国际模式在很大程度上依赖源文本的自观察机制来培训这些模型,方法是向这些模型提供大量数据,使这些模型能够记住输入的文本。
虽然变形器证明相当有效,但缺陷很少:
时间和空间过于复杂,需要大量的可见卡片和记忆。
当数据不够的时候 变形器的功能就不够好
另一方面,从本质上讲,变形器是一个黑盒模型。他不可能像正常生物一样阅读和思考。关键是要了解大赦国际为什么作出这种预测。KERA通过使用知识地图、词典和公开提供的机器来学习数据常识。对答复的来源以及模拟推理方法有些敏感。
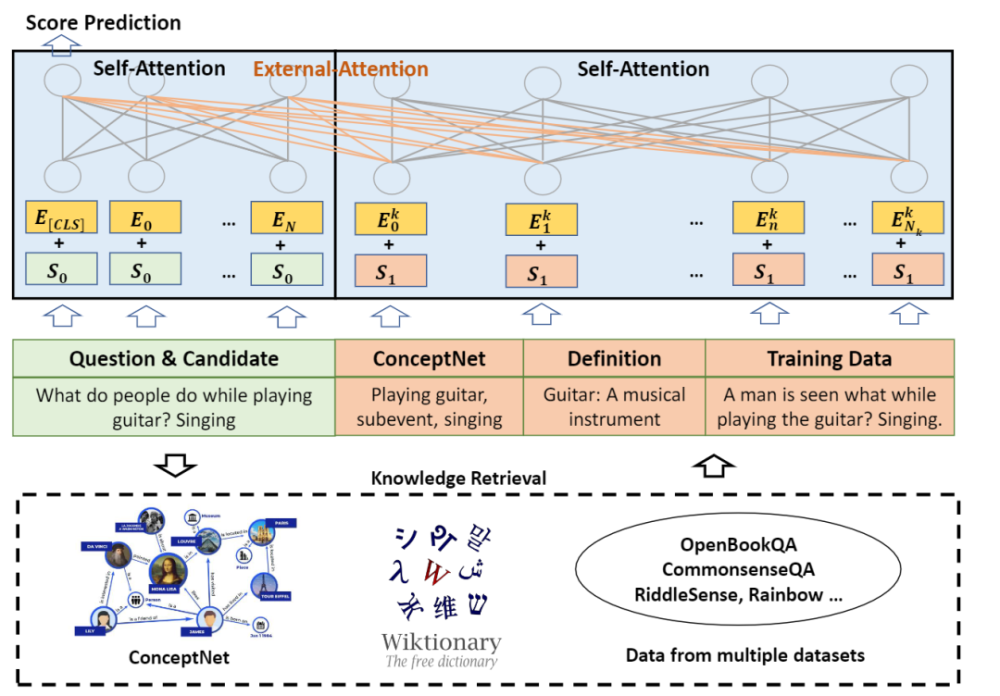
通过将投入(投入)和知识(知识)水平合并为新的投入,然后通过自我考虑机制将整个系统变成H0,也可以获得外部关注。
知识地图概念网、词汇和培训数据都是知识(知识)的来源。
可以看到,注意力和外部注意力的主要区别在于投入是否完全来自案文。换言之,通过向外部关注进程提供许多来源的重要背景和知识,它包括知识地图、词典、语言图书馆和其他语言模型的产出。然后,让模型既注重投入,又注重知识之外的世界。有可能产生增加外部知识的影响。
引进的外部信息储存在符号(符号)中,如纯文本或知识简介条目,这提高了变换器掌握语言的能力。
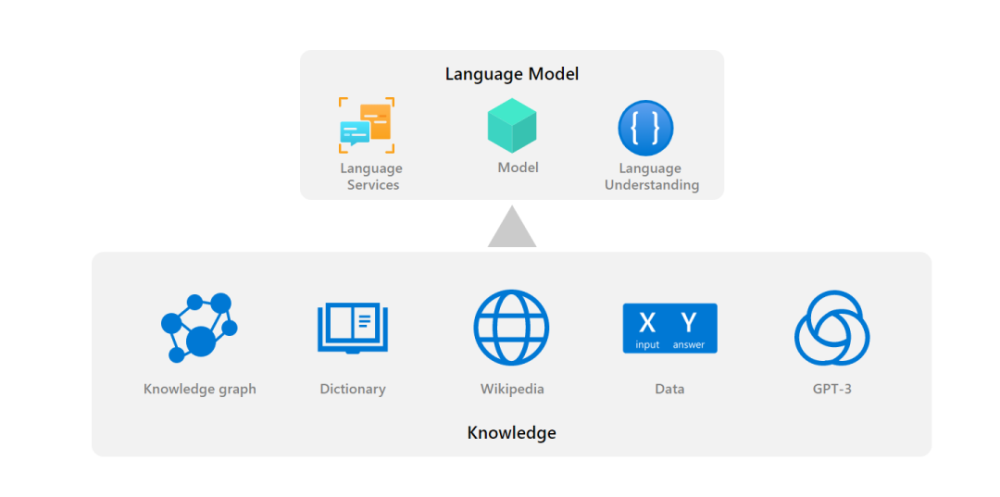
此外,KEAR使用的输入和知识的文本级联不会影响变换模型结构,使现有系统能够简单地应用外部注意力。
由于环境中的信息也是动态的,外部关注的另一个好处是用户可以简单地更新其知识来源,以修改模型的预测产出。
通过纳入最新的常识,例如将更新的在线知识地图纳入模型,可以使模型的决策过程更加明显和易于解释。
多模块优化与外部关注知识库相结合,也是提高微软AI服务质量的重要途径。
作者介绍
徐一是这篇文章的最初作者在姚课上,我从青华大学毕业卡内基梅隆大学授予他博士学位。主要研究重点是交互式机器学习。深入学习和自然语言处理他目前是微软AI认知服务研究组的高级研究员。

朱晨光是微软认知服务研究组的首席研究主任他负责知识和语文小组。在文本总结、知识绘图和面向任务的讨论等领域进行研究和开发。2016年,他从斯坦福大学毕业,获得计算机科学博士学位和统计学硕士学位。在此之前,曾获得青华大学姚级计算机科学学士学位。

黄晓东领导微软的人工认知工程和研究团队IEE/ACM下士、IEE/ACM研究员微软的第一位中国全球技术专家、微软首席语音科学家、微软云计算和人工智能认知服务小组的全球技术硕士/全球人工智能首席技术官湖南大学授予他学士学位。英国青华大学硕士学位和爱丁堡大学博士学位。

参考资料:
https://arxiv.org/abs/2112.03254