
我们以前对卡夫卡的了解很简陋,现在希望加以应用。
在利用Kafka之前,必须先安装。
Kafka支持单一机器和集束模型,建议在整个学习阶段只使用一个机器模型,不区分单一机器和集束操作。
因为Kafka依赖Zookeper, 我们必须首先安装Zookeper。
I. 部署Zookeper安装
1. 安装一台单一的Zookeper机
Zoomaner02: 安装 Zookeper [单台电脑]
2. 安装Zookeper集束器
动物园管理员03:动物园管理员部署装置[组
安装后,动物园管理员集群可开始安装卡夫卡。
必须指出,动物园看守组在安装卡夫卡之前必须处于启动状态。
Kafka还必须依赖基本环境jdk并确保安装。
二. Kafka单机安装
1:下载Kafka安装软件包。
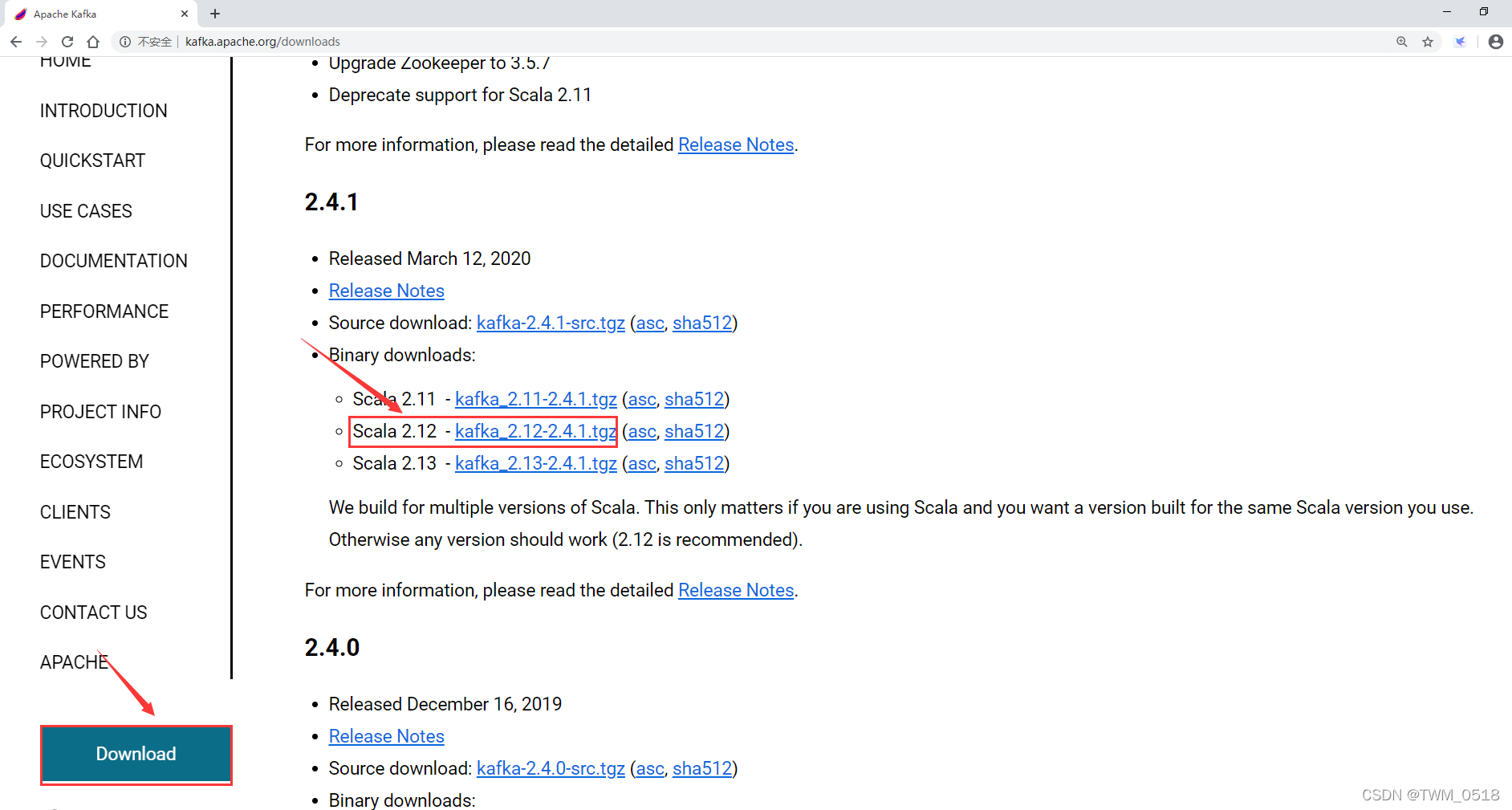
最终下载链接如下:
kafka_2.12-2.4.1.tgz
百度网盘地址:
由于Kafka在jvm虚拟机器上运行,只需要jdk环境,所以在启动时不需要安装scala环境,而只是在编译源代码时才需要安装。
3: 将卡夫卡安装包复制到 Bigdata01 / data/ sft 目录 。
3:解压
4:修改配置文件
主要参数:
如果 Kafka 和 动物园keper 在同一台计算机上, 而动物园管理员正在监听的港口是 默认端口 2181, 那么动物园管理员 。 此选项不需要为单一机器模式更新 。
唯一需要更改的是日志。 目录是好的 。
5:启动kafka
6:验证
启动成功后,将生成一个 kafka 进程 。
7:停止kafka
三. Kafka集群正在安装。
1: 集束节点打算用三个节点建造一个kafka群集。
注:Kafka集群没有很大的鸿沟,所有节点都是一样的。
首先,在Bigdata01节点上配置 kafka 。
(1)解压:
修改配置文件
抱歉, 代理商。 id 的值预计将从零开始, 即组群中所有节点的代理商 。 id 从零开始 。
因此,Bigdata01节点的经纪人.id价值为0。
我不知道你们在说什么。Dirs的价值应该被分配到 存储容量更大的磁盘上, 因为 Kafka 存储了很多数据, 我在我的虚拟机器里有一个磁盘, 因此它被分配到/数据目录上。
不不,不,不,不,不,不, 不,不,不,不,不,不,不,不,不,不,不,不, 不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不。
3: 将更新的卡夫卡安装包分发给其余两个节点。
4: 修改关于卡夫卡的数据02和bg数据03
然后,我们必须把大数据02节点的经纪人修改为1。
接下来,在Bigdata03节点上, 我们将改变经纪人的身份。 id 设为 2 。
5:启动集群
开始关于Bigdata01、Bigdata02和Bigdata03的卡夫卡进程。
(1) 从Bigdata01开始。
(2) 从Bigdata02开始。
(3) 在Bigdata03上开炮。
6:验证
在 Bigdata01、Bigdata02和Bigdata03 上运行 jps 命令以检查 kafka 进程 。
如果一切都存在,它意味着卡夫卡集群正在正常开始。