
Kafka学习手册
本文摘自:
https://ww. un. org/I'm sorry, Orchid。这是我们对2011年叙利亚抗议的特别报导的一部分。
Orhouse是源头
0. 预备动作
- 安装java
下载软件包:
抑郁症已经足够,卡夫卡依赖动物园来管理。 卡夫卡执行器的分布已经包括动物园管理员,不需要独立安装的动物园管理员。
1. zookeeper
1. 开始动物猎食者
Kafka的安装软件包包括自足的动物园管理员启动软件,而且由于Kafka的集束模式依赖于动物园管理员,你必须先启动动物园管理员,然后才能启动。
1. 利用当地动物猎犬
Kafka 可以使用本地的动物园keper。 属性剖面图中的剖面图通常使用 Kafka 持有的动物园管理员脚本 。
2. 应安装卡夫卡。
- 开始管理员服务器 :
- 然后运行 kafka:
- Ps 查看服务现已投入运行:
- 创建topic
- 动物园管理员:选择动物园管理员的角色。
- 将复制因子设为 1 。
- 分区 : 为此专题设定三个分区 。
- 设置主题名称 。
为了找出存在什么主题, 请使用主题命令 。
- 创建生产者
使用 kafka 命令 :
- 中间商列表 : 此参数指定了 Kafka 节点列表 。
- 专题:从制作到专题的讯息
我们将输入命令互动页面, 切换到不同的终端窗口, 并创建一个消费者。
- 创建消费者
使用以下命令创建消费者 。
- 陷阱服务器: 定义 kafka 节点 。
- 消费是主题。
- 从一开始:消费从一开始开始,即只要消费者启动,如果不存在字段,则从消费者提供的最新信息开始。
- 发送数据
消费者将能够印刷生产者互动网站上输入的材料。
三. 卡夫卡的概念
3.1 基本概念
- 制作人:创造信息并发送到卡夫卡主题节目的人。
- 订阅 Kafka 专栏作为电文的用户 。
- 消费者群体:你可以为某一主题向许多群体发送信息,但每个群体只有一个消费者接收数据。
- 经纪人(物理概念):卡夫卡应用程序所在的服务器,基本上是卡夫卡的卡夫卡节点。
- 主题(逻辑概念):这是将数据分割和分离的卡夫卡信息类型。
- 分区(物理概念):卡夫卡数据储存单元。一类数据将保存在该国不同地区,另一类数据将储存在该国各地。每次庆祝活动都是组织完善的。卡夫卡会把派对交给经纪人国家使用的卡夫卡设计具有多种功能。一个好处是,我们可以管理更多的数据。单一服务器不受任何限制。专题有几种关系,可以不受限制地处理更多的数据。第二,分区可用作平行处理单位。
- 每个专题分为若干节。
- 参与少于或等于客户人数。
- 经纪人集团中每个经纪人集团中的每一个经纪人都省去了 " 专题 " 的一个或多个部分,因此一个以上的经纪人将不保留任何组成部分。
- 当盛大庆典到来的时候它是全球的一部分,可能由一批经纪人集体储存。这种情况,每个经纪公司都有不同的数据。也就是说,它仍然是一个同时在许多地点并不存在的当事方。
- 只有一个消费者集团和一个消费者阅读一个主题的一个或多个部分,主要是为了避免一当事方被许多消费者吞噬。
- 重复:同一分区内可能存在若干带有相同数据的复制件。
- 当经纪人在集群内时,系统可主动寻找提供服务的复制品。
- 系统为每个主题设定默认系数为1,即默认不会重复,当主题形成时可以独立改变。
- 主题分割是复制的基本单位。
- 领导者是所有阅读和写作的来源。
- 跟踪者必须能够及时复制领导者的数据。
- 添加到错误容忍度和可缩放性上。
- (a) 复制带头人:一个通过许多复制品与生产者和消费者沟通的政党。
- 复制管理器: 管理关于所有分区的信息和当前 Broker 的复制件, 处理 Kafka 控制器请求、 修改、 添加、 读取等等 。
3.2 kafka Api
- 通过制作人API向一个或多个专题(主题)发送信息。
- API: 此 API 允许您订阅一个或多个主题并处理生成的信息 。
- Strams API:作为流程处理器运作,接收一个或多个主题消费者的投入,并将产出流制成一个或多个主题,从而将输入流转换成产出流。
- API 链接器: 可能创建或实施可重复使用的生产者或消费者, 并与现有应用程序或数据系统连接同专题。 例如, 附属于关系数据库的连接器可以记录表格中的任何变化 。
3.3.1 kafka电文格式
[外国连锁照片传送失败;发端站可能有一个隐形链机制;直接下载和上传图像(img-qrGLqLD2-16471886562134)(images/1).jpg)]
Kafka 的电文字段 :
- 外部设置: 跟踪当前信件偏差
- 讯息的长度:有多长?
- CRC32:确保信息的完整性
- 魔力: 确定信息是否为卡夫卡, 如果魔法的价值与集不符, 迅速确定信息是否为卡夫卡的 。
- 属性:可选;可以包括某些属性字段和列举。
- 时间戳是一个时间戳。
- 密钥长度 :
- Key: Key: 没有长度限制
- 价值长度:长度
- 价值没有长度限制。
三.4kafka属性
- 分布式
- 多分区
- 多副本
- 多订阅者
- 以动物看管者为基础的调度
- 高性能
- 高吞吐量
- 低延迟
- 高并发
- 时间复杂度O(1)
- 持久性和拓展性
- 数据可持久化
- 容错性能,多副本等
- 支持在线水平拓展
- 信息是自动平衡的,因为它们的目标太过明确,无法进入特定的计算机。
四. Kafka申请中的场景
- 信件队列, 大多用于点对点通讯
- 订阅扩展、行为跟踪
- 云层信息监测(主要是业务信息)和运输审计
- 例如收集日志。 ELK、 HDFS 等。 对于日志数据, Kafka 可用于创建日志流 。
- 与Strom类似,液体处理利用原来的主题进行汇总,然后放入一个新的主题。
- 资料来源:重新追踪状况,将其转入一个时间序列。
- 持久性有机污染物日志(委员会日志),该日志主要使用日志回归来恢复数据。
4.1 消息模型
信息模式分为两大类:
队列:队列由一群从服务器阅读的消费者管理,其中只有一个人管理。
订阅后:信息向所有消费者广播,由收件人处理。
然而,卡夫卡通过雇用一个共同的消费者群体来解决上文讨论的两种信息模式。
- 问题:每种消费都被列为消费群体。
- 订阅:理想的情况是,每个客户只属于一个消费者群体。
一般而言,每个消费群体有两个或两个以上的消费者,一个群体中有许多消费者可以提高业绩和容忍度。
如下:
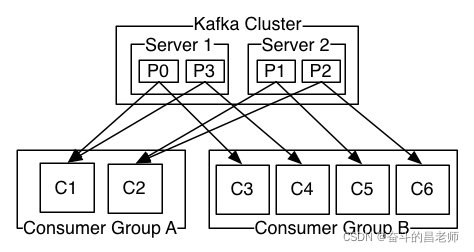
四.2 确保电文的发送顺序相同。
Kafka 保证信件序列不会改变 。为了让信息保持生命, 它和典型的队列机制相似。他们将永远保持同样的顺序。另一方面,Kafka保证Kafka服务器上的信息序列相同。这并不是顾客将遭遇的唯一事情,但消费者也会遭遇同样的事情。无法保证向客户提供信息的顺序。这也意味着同时消费不会确保信息排序。如果只允许一个消费者处理新闻这也违背了同时治疗的预期目的。
此时,卡夫卡表现更好。尽管上述缺陷尚未完全解决。Kafka采用分区和规则方法,称为分区。从消费者群体获得信息是不可行的,因为Tople的分区新闻只能由消费者群体的唯一消费者之一处理。此外,要确定客户是这一合作的唯一受益者。并按顺序消费数据。因此,信息必须按顺序处理。然而,这只是一个确保主题的分治秩序。无法保证按各司收到的顺序处理来文。所以,如果你想处理一个主题的所有信息 井井有条那就制造分裂吧每个专题分为若干节。各种客户的负担必须平衡。
请记住,同一消费群体中的客户不能多于同一消费群体中的客户;否则,更多的消费者将一直等待,得不到信息。
- 由制片人发送至特定主题部门。将按收到的顺序添加电文。也就是说,如果信息M1和信息M2都是由同一制片人发送的M1先发送,因此,M1将低于M2补偿。优先在日志中显示。
- 客户获得的信息也是如此。
- 如果 " 主题 " 将复制系数设定为N,则可以允许N-1服务器在不丢失任何提供的数据的情况下失灵。
在卡夫卡语中,消费群体有两个概念:
- 问题:消费者集团(消费者集团)允许同一消费者集团的成员得到个别待遇。
- 订阅:使您能够向不同的消费者群体(以不同名称)发送信息。
这两种模式可在Kafka的每个专题中找到。
四. Kafka 3个实例的储存和流数据:
作为储存系统,四、三.1
Kafka是一个非常快速的储存系统。为实现对过失的容忍,写给卡夫卡的数据将写成软磁盘并传送到组群。这是世界历史上第一次。直到消息完全写入。卡夫卡的磁盘结构 - 如果你的服务器有50KB或50TB,执行是相同的。
您也可以将Kafka视为一个分布式文件系统,专门用于高速、低潜伏、日志提交存储、复制和分发特殊应用程序。
关于流数据处理,四.三.2
阅读、写作和储蓄不足,卡夫卡的目标是实时流程处理。
Kafka 的溪流处理持续收集收到的数据,处理数据,然后生成产出主题。例如,考虑零售APP,该APP接收销售和输出的投入流量,计算数量,或修改产出定价。
基本处理可由生产者和消费者API直接进行,对于更先进的转换,Kafka提供较富的气流API。这是一个复杂的应用,可以制造聚合物计算或相互连接。
协助解决这类申请所遇到的困难:
- 处理无序的数据
- 代码更改的再处理
- 执行状态计算等。
Kafka中心处的溪流API:将生产者和消费者API用作投入,将Kafka用于国家储存,以及处理溪流处理器示例之间故障的同一组机制。