
1. scrapy 日志信息和日志等级
1.1 scrapy 日志级别
- CRITICAL:严重错误
- ERROR: 一般错误
- WARNING: 警告
- INFO: 一般信息
- DEBUG: 调试信息
默认的日志等级是DEBUG,只要出现了DEBUG或者DEBUG以上等级的日志 那么这些日志将会打印。
1.2 创建项目测试
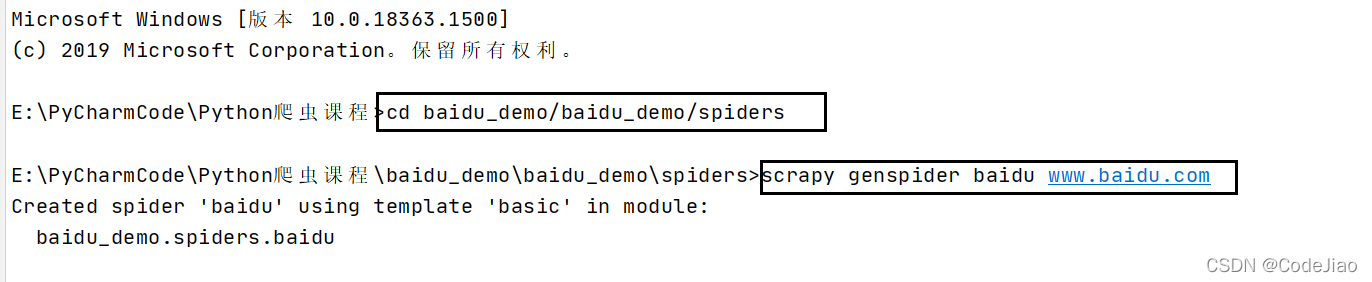
创建爬虫的项目
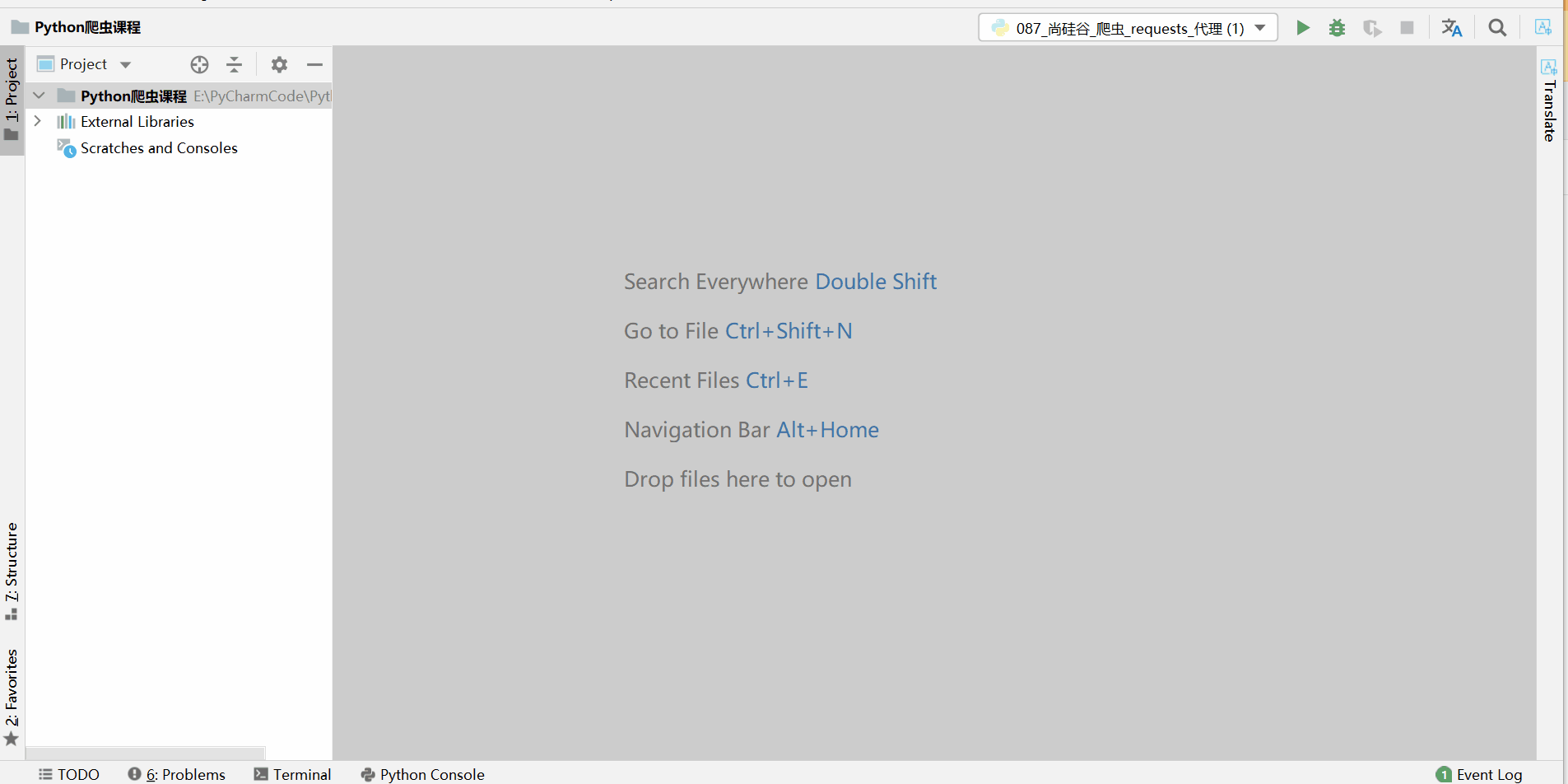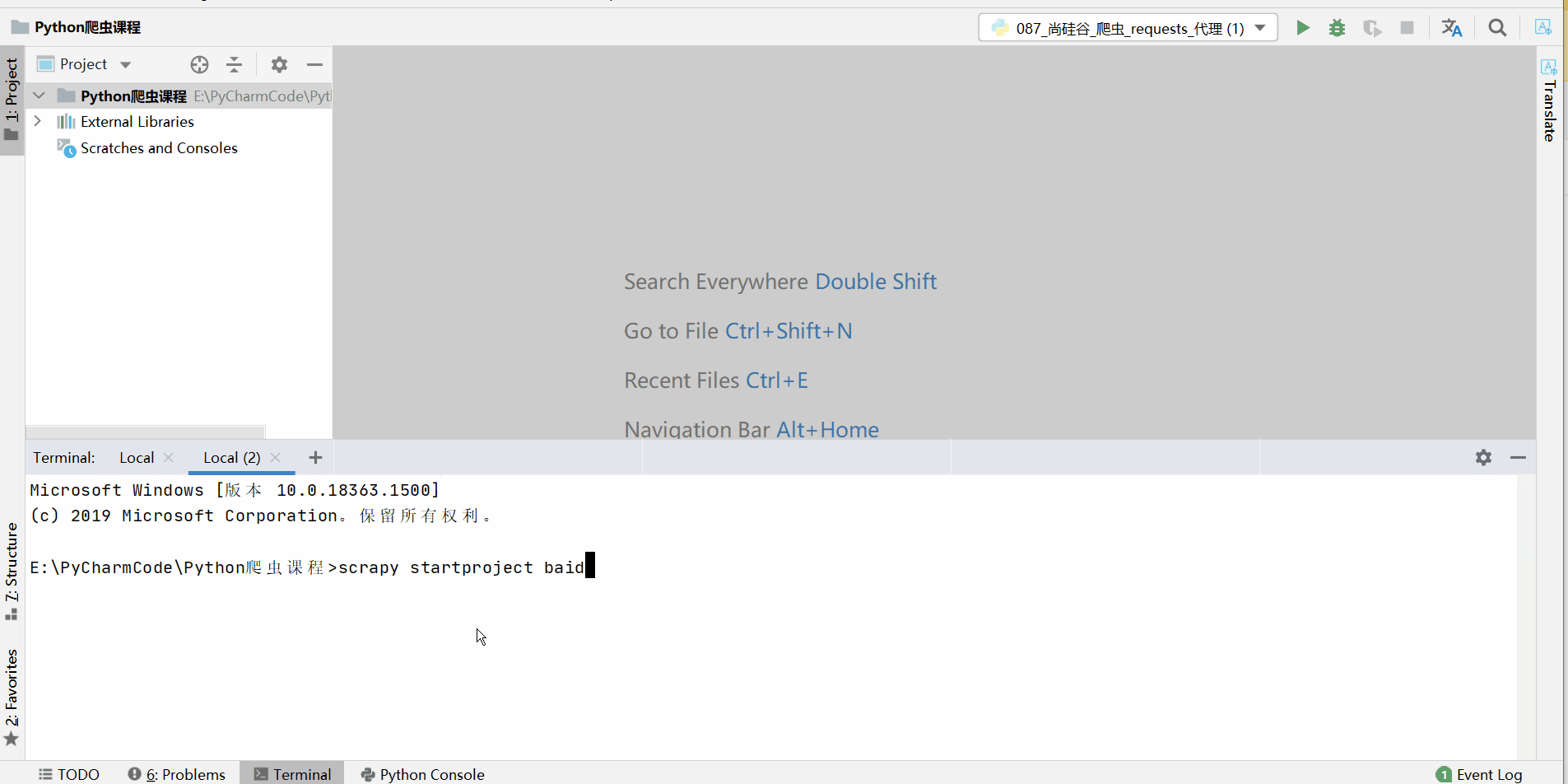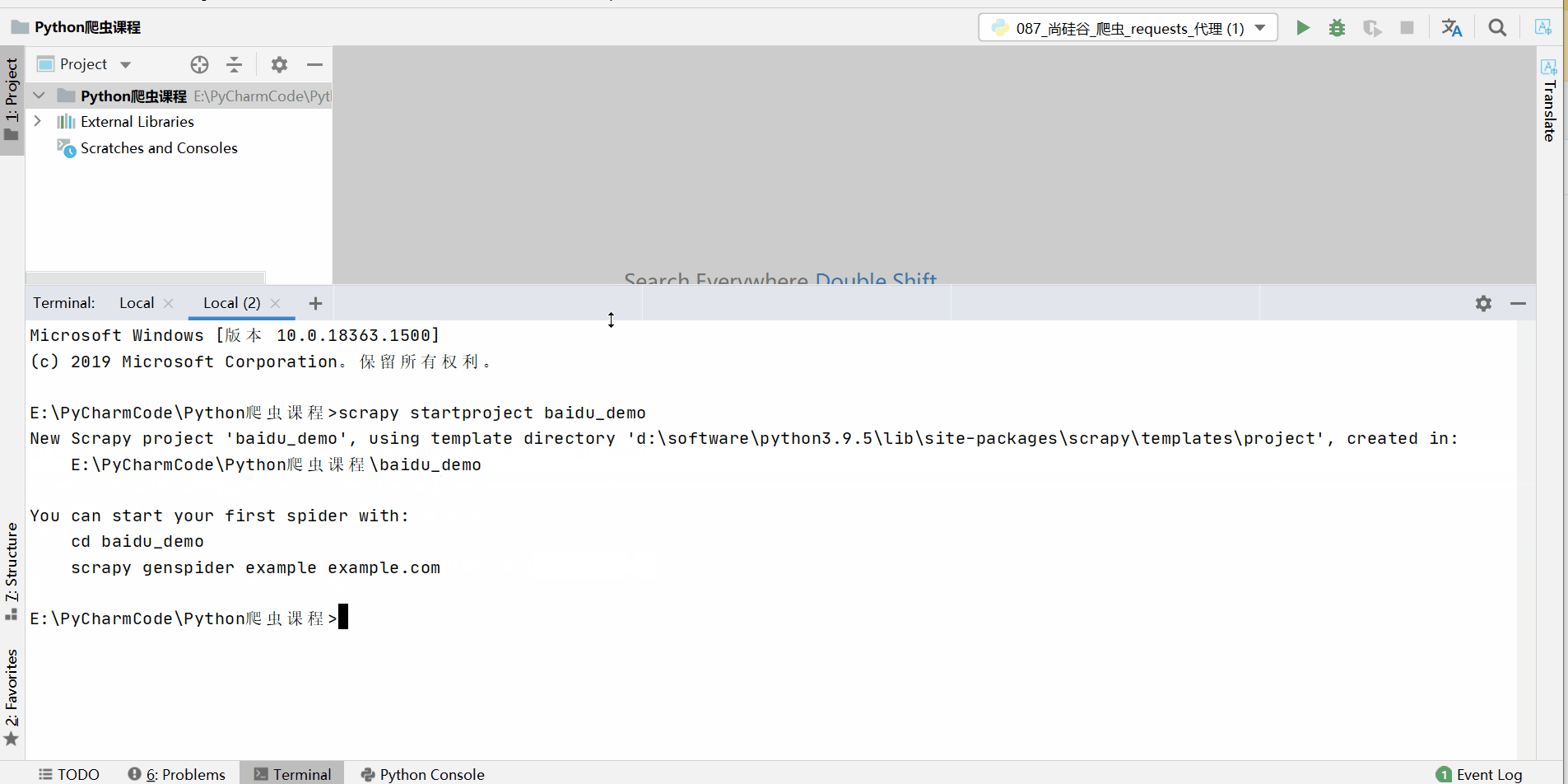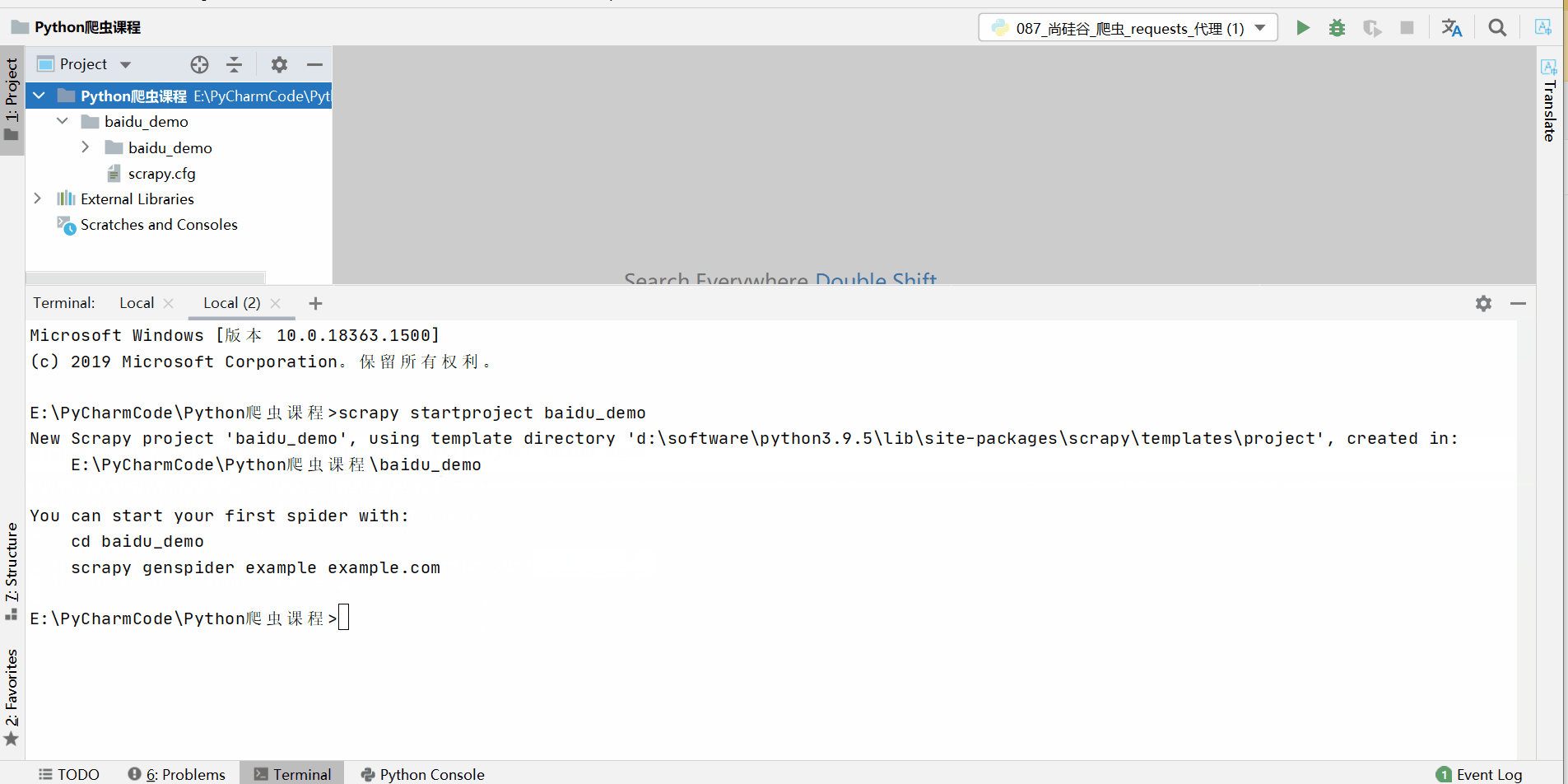
在目标目录终端输入:scrapy startproject 项目名称( 注意:项目的名字不允许使用数字开头 也不能包含中文)
我这里输入的是scrapy startproject 百度
创建爬虫文件:
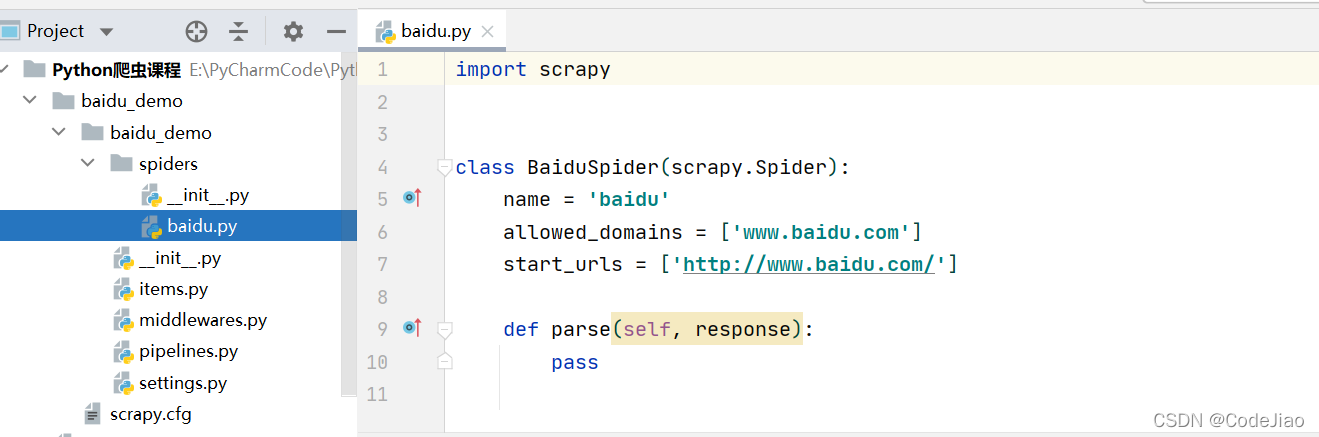
baidu.py
一般情况下把allowed_domains和start_urls改为一样,因为后缀会.html的url加上/会报错
运行爬虫代码:

我们发现存在一个robots协议(这是一个君子约定,就是说你不可以爬百度)阻止我们继续访问:
在游览器输入https://www.baidu.com/robots.txt就可以查询百度的robots协议了。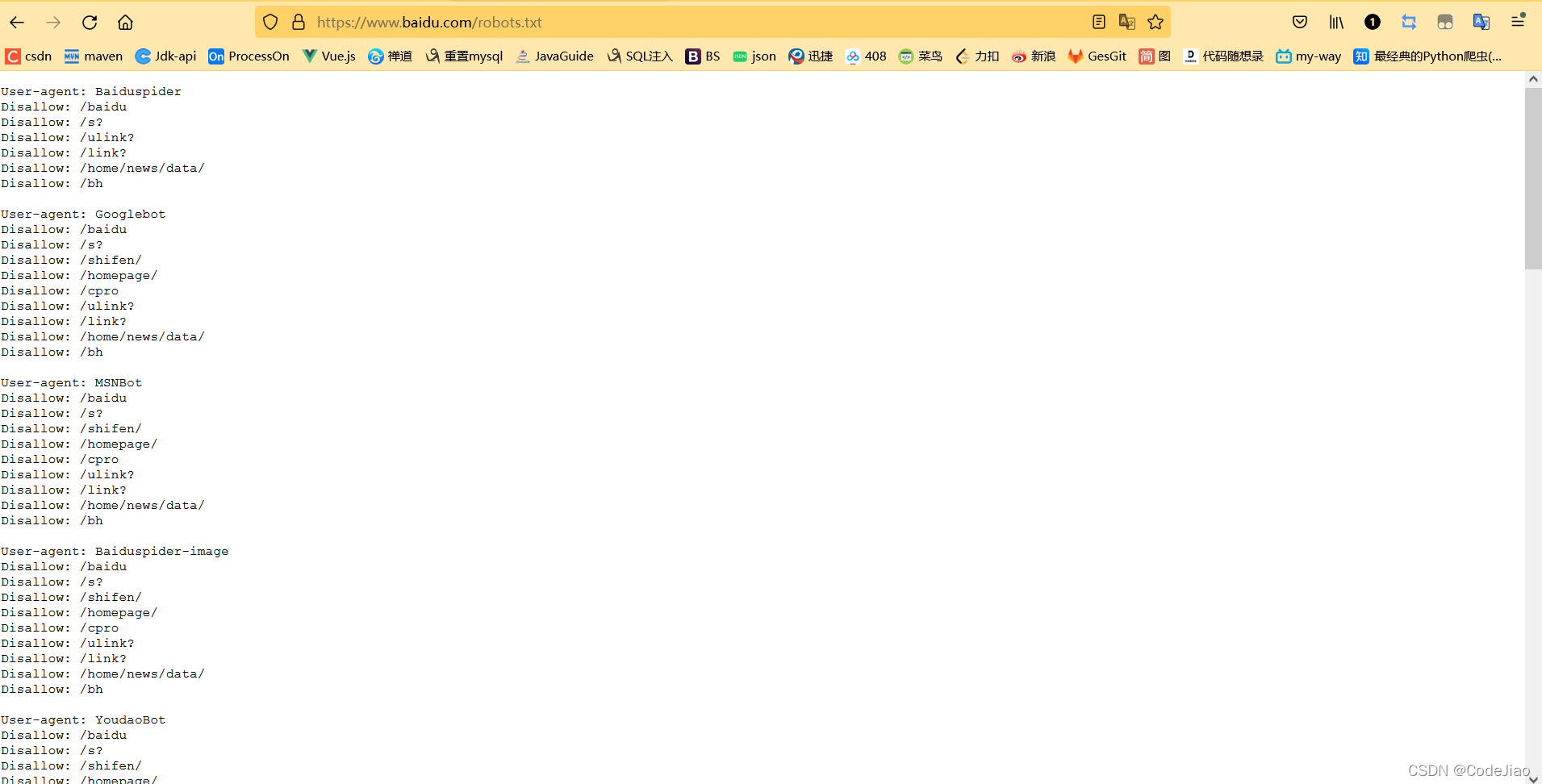
关闭遵守robots协议(创建项目时 默认遵守)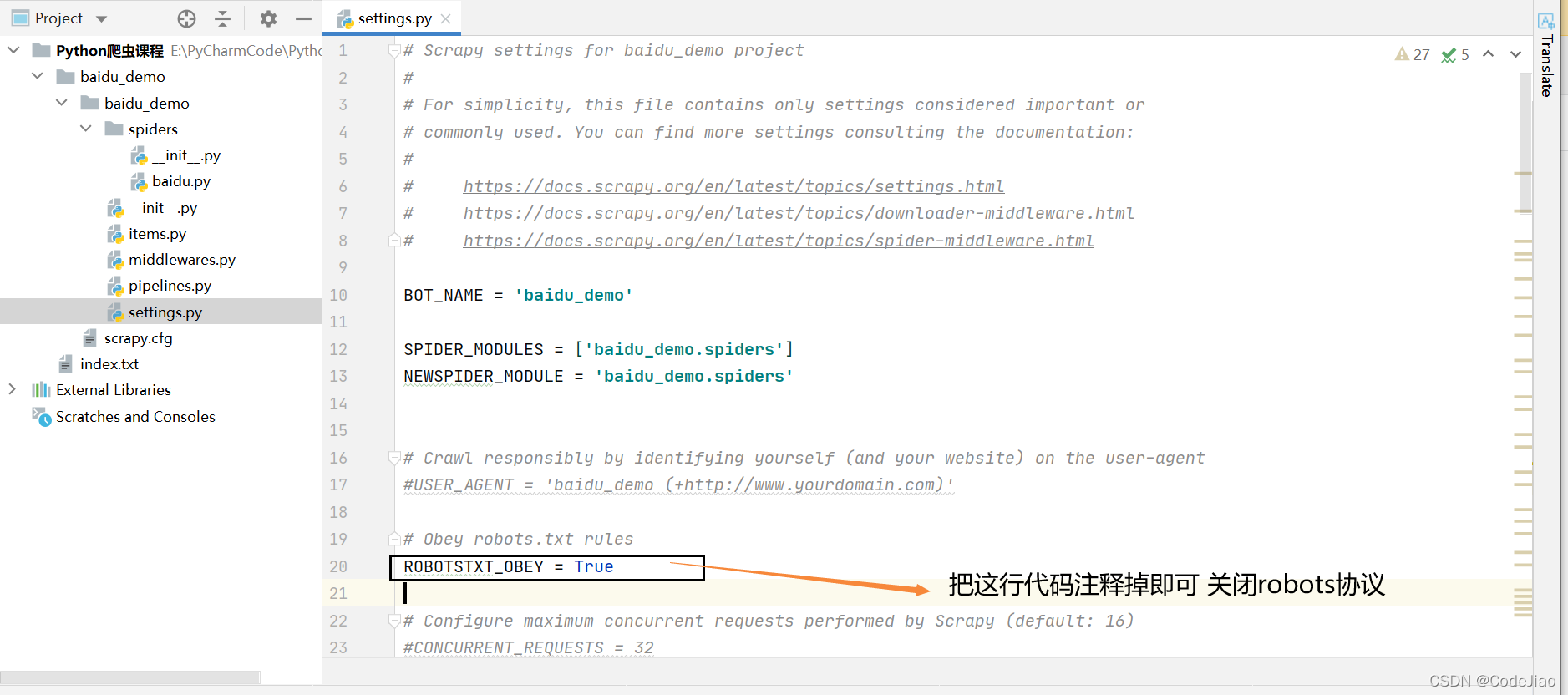
再次运行:访问成功
可以看见,打印了许多的信息,看去来比较繁杂。

1.2 settings.py文件日志等级设置
默认的级别为DEBUG,会显示上面所有的信息。
在配置文件中 settings.py 中
- LOG_LEVEL : 设置日志显示的等级,就是显示哪些,不显示哪些。
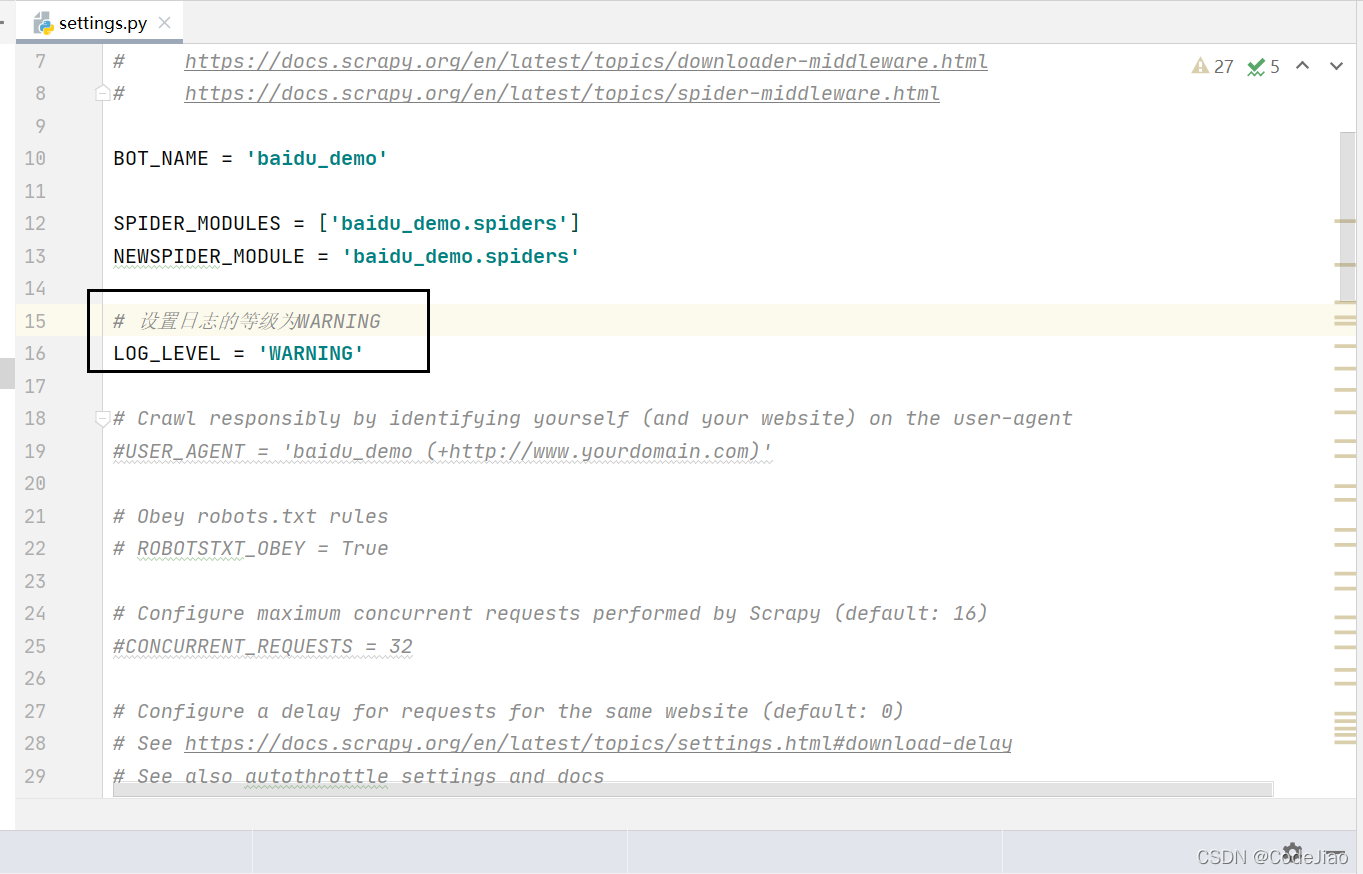
再次运行的结果,发现现在只有我们打印的信息。
- LOG_FILE : 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.log (推荐使用),上面那种做法太极端了,这样的话,出错了我们就不可以看到错误信息了,没办法去调试。

再次运行的结果

2. scrapy shell的使用
2.1 什么是 scrapy shell ?
Scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。 其本意是用来测试提取 数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。 该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。 在编写您的spider时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。 一旦熟悉了Scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
2.2 安装ipython
安装:
pip install ipython
简介:如果您安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相 比更为强大,提供智能的自动补全,高亮输出,及其他特性。
如果想看到一些高亮 或者 自动补全 ,那么可以安装ipython。
2.3 scrapy shell的使用
进入到scrapy shell的终端 :直接在window的终端中输入scrapy shell 域名
eg:
scrapy shell www.baidu.com
语法:

eg: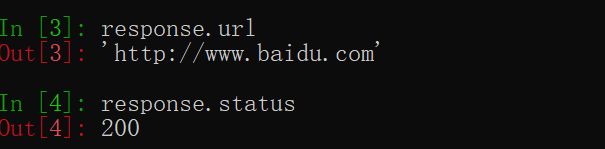
tips:在scrapy shell中输入的时候,按tab键可以调出提示。
3. scrapy post请求
我们抓取百度翻译的这个请求。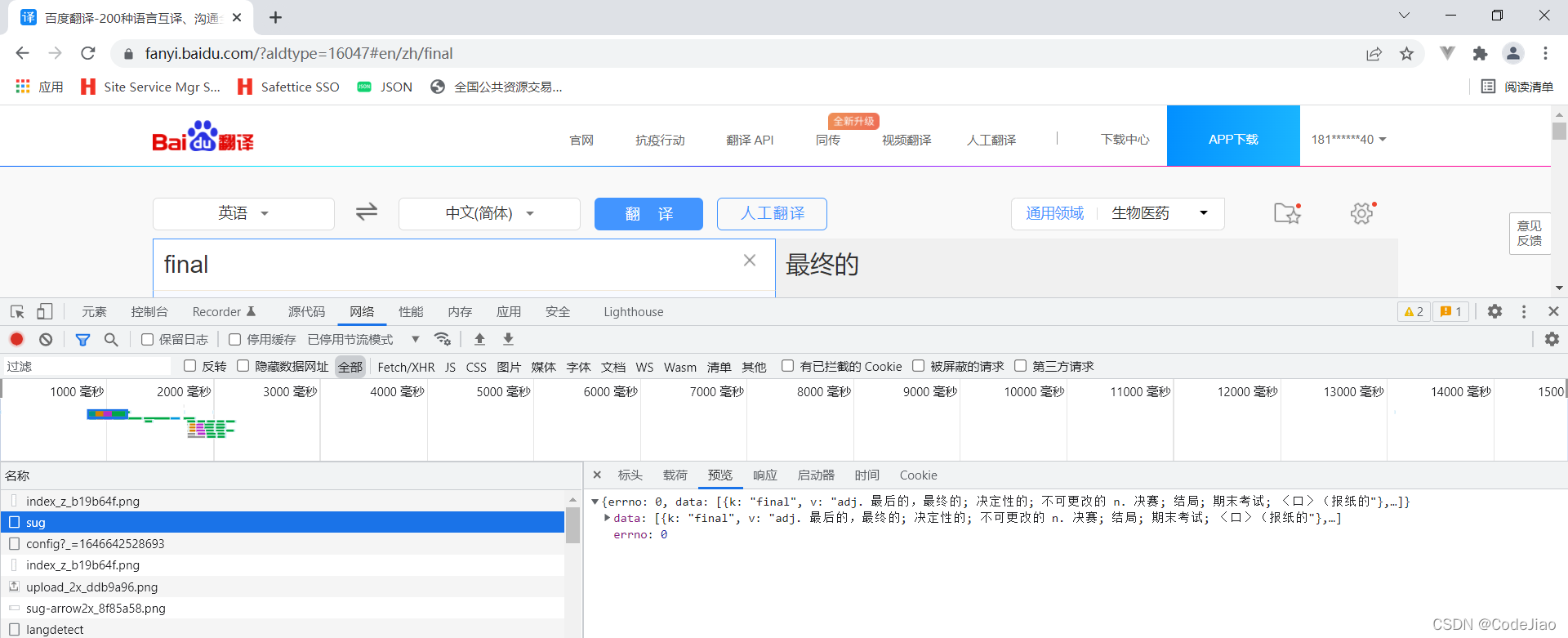
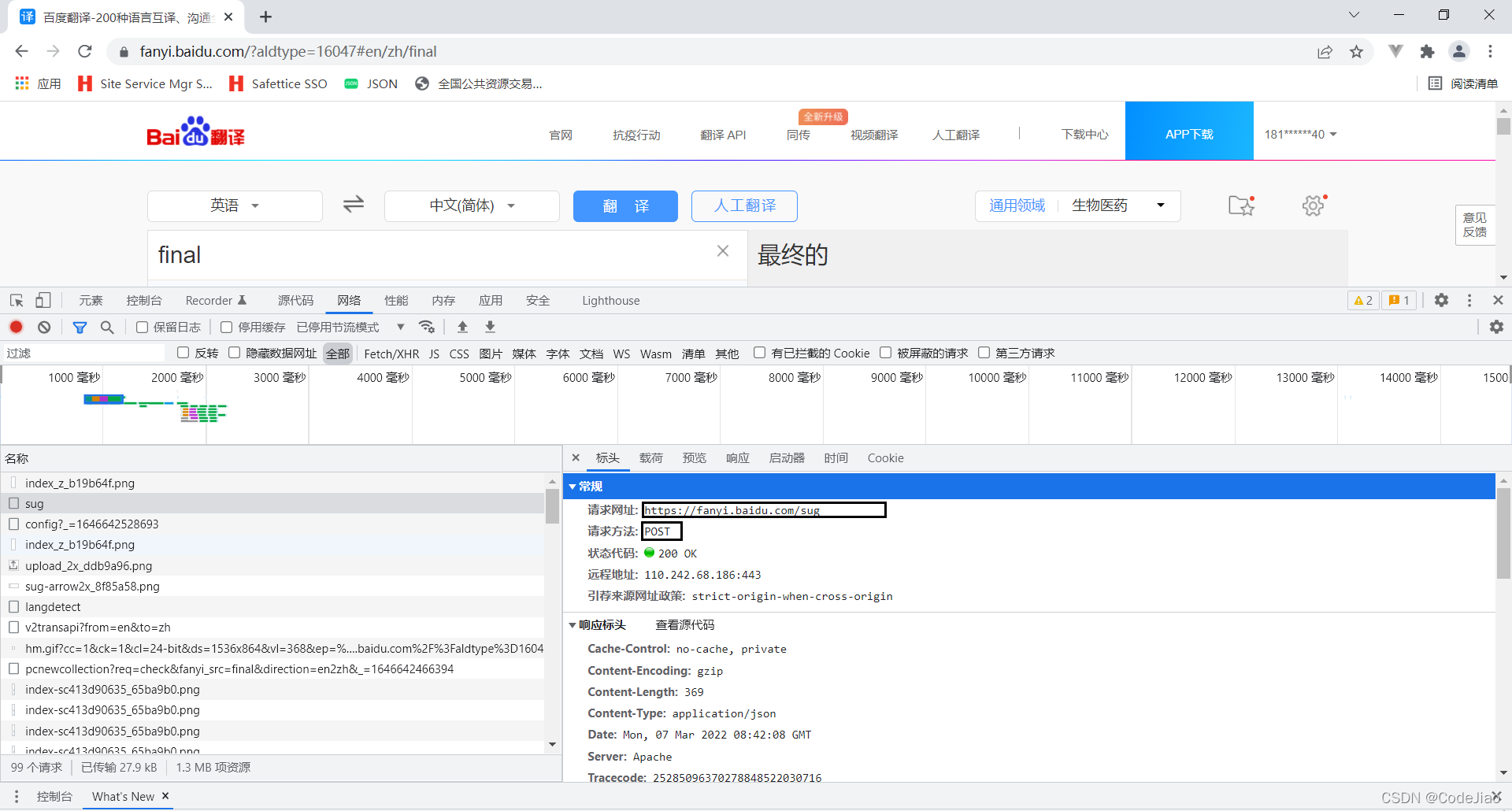
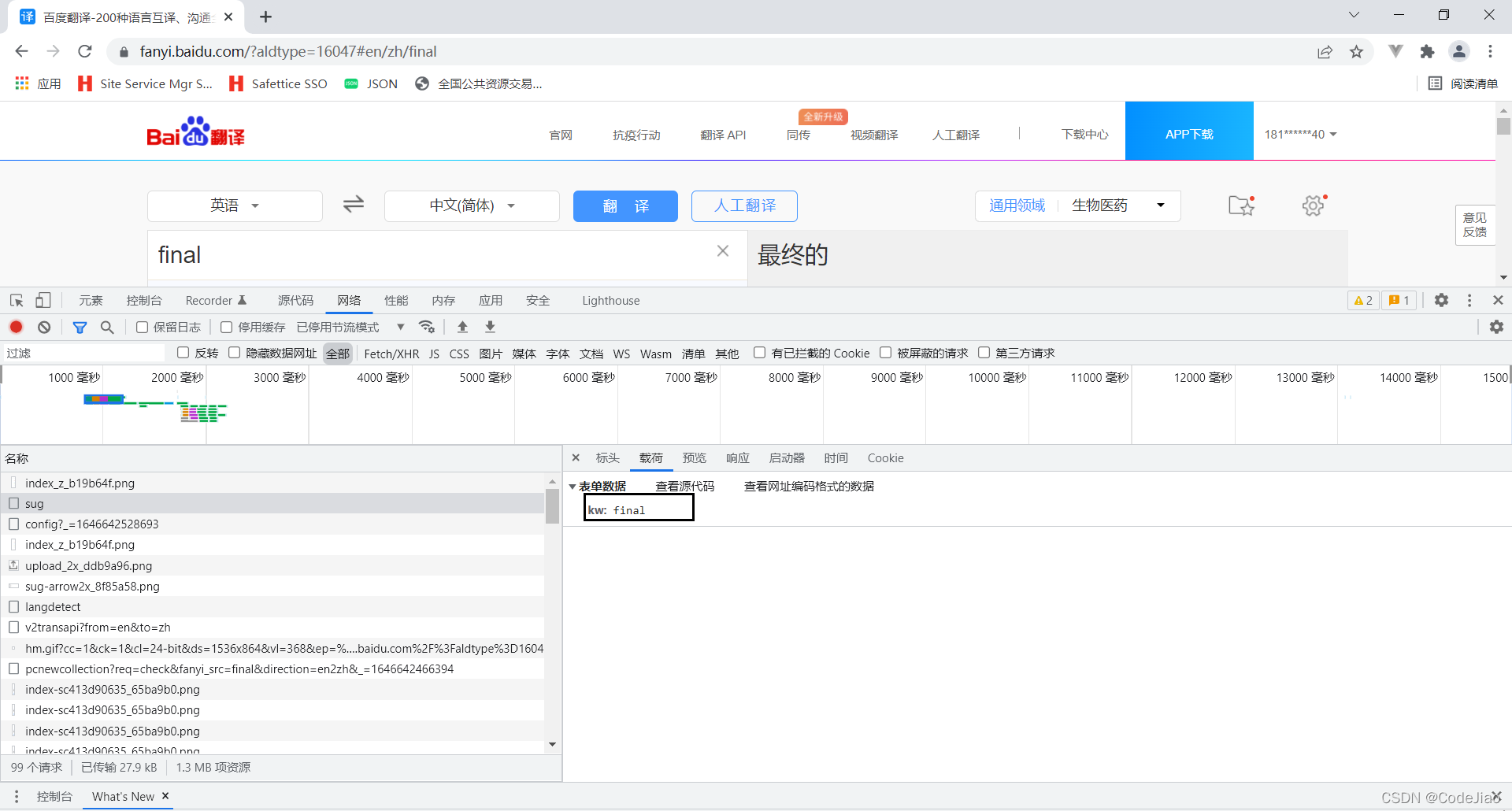
现在把第一个项目的baidu.py的替换一下
现在的运行结果:
