
《
OpenShift 4.x HOL教程汇总
》
本文介绍功能属于 OpenShift 4.10 新特性。
文章目录
- 不可变(Immutable)特性提升 OpenShift 可管理性和安全性
- Machine Config Operator 和 Machine Config 的作用
- 什么是配置漂移
- 形成配置漂移
- 处理配置漂移
- 手工恢复配置
- 强制恢复配置
- 参考
不可变(Immutable)特性提升 OpenShift 可管理性和安全性
对于 Kubernetes 集群,无论是在 Master 还是 Worker 节点上运行的 systemd、Kubelet、proxy 等核心服务或模块都是直接运行在 Linux 操作系统上面的。由于这些关键配置都可直接在 Linux 中直接修改,这就给 Kubernetes 集群带来可维护性问题以及运行安全问题。
- 不同的维护人员在不同时间修改这些配置,导致 Kubernetes 集群的不同节点出现不同的配置,从而维护变得越来越混乱。最终可能因为可维护性的问题出现 Kubernetes 集群运行异常。
- 对 Kubernetes 运行所依赖的关键服务活模块进行不适当配置,导致该容器运行节点出现安全隐患。致命的是这种基于错误配置的安全隐患管理员很难跟踪察觉到。
为此 OpenShift 结合底层支撑的 Linux 操作系统 - RedHat CoreOS Linux(RHCOS)为 OpenShift 提供了 “不可变(Immutable)特性”,从而能有效提升集群节点的安全性,并极大降低了对 Kubernetes 集群节点的主机维护管理工作量和难度。
OpenShift 的不可变特性并非是让管理员无法对运行 Kubernetes 集群的 Linux 节点进行任何更改,而是最大限度让这些更改成为**可控(即便root用户也不能对所有文件进行修改)、可跟踪(记录对操作系统关键服务配置进行的更改)**的操作。OpenShift 的不可变特性表现在以下几个方面:
- 即便是 root 用户也只能修改 RHCOS 中的 /etc 和 /var 目录,而其他目录都是 readonly 的。
- 通过 OpenShift 的 Machine Config Operator 机制管理运行在 RHCOS 上的诸如 systemd、Kubelet、proxy 等 Kubernetes 依赖的核心服务的配置。
- 对 OpenShift 集群的操作系统 RHCOS 进行升级过程有些类似容器镜像的更新,即在更新过程中,RHCOS 升级的新环境不会覆盖旧版环境。只有在 RHCOS 重启后升级的新版环境才能全部生效。这样就能确保在 OpenShift 集群整体升级过程中即便有一个节点出现问题,这个节点和其他没问题的节点能回退到升级前的版本。
Machine Config Operator 和 Machine Config 的作用
在 OpenShift 集群中 Machine Config Operator(MCO)负责管理运行在 OpenShift 集群节 RHCOS 点上的 systemd、CRI-O 和 Kubelet、Kernel、Network Manager 和其他系统功能是如何更新的。MCO 通过 MachineConfig CRD 把配置文件写到主机上。为了实现对 OpenShift 集群进行系统级的修改和高级管理、必须了解 MCO 的作用以及它与其他组件的互动方式:
- Machine Config 用来改变 OpenShift 集群中每个节点的系统的操作系统上的文件或服务。
- 用 MCO 对 Machine 中的操作系统进行更改。所有 OpenShift 集群开始时都有工作平面和控制平面节点池。通过添加更多的角色标签,你可以配置自定义的节点池。
- MCO 管理在 Machine Config 中设置的项目。你对系统所做的手动修改不会被 MCO所覆盖,除非 MCO 被明确告知要管理一个冲突的文件。换句话说,MCO 只做你要求的特定更新,它不要求对整个节点的控制。
- 不鼓励对节点进行手动更改。因为如果这个节点退出集群,所有手动修改都将丢失。
- OpenShift 的 MCO 只能修改 /etc 和 /var 目录下的文件,另外还有通过符号链接到这些区域的目录,例如 /opt 和 /usr/local。
可以使用 MCO 来修改节点的以下配置:
- 配置- 通过 Ignition 修改
Configuration files - 在 /var 或 /etc 目录中创建或修改文件
systemd units - 创建或修改 systemd service
users and groups - 修改 passwd 的 SSH 秘钥 - 系统内核参数 - 添加集群节点启动使用的内核参数
- 系统内核类型 - 选择非标准内核,例如 realtime 内核
- FIPS - 允许使用 FIPS 模式
- 扩展 - 通过增加软件包扩展 RHCOS 特性
- 定制化资源 - 修改 ContainerRuntime 和 Kubelet 配置
查看 OpenShift 的 MachineConfig 对象
查看一个 “rendered-worker-xxxxx” 对象,其中包含由 OpenShift 的 MachineConfig 维护的配置文件。
什么是配置漂移
在 OpenShift 运行的时候,一个运行 RHCOS 的节点的状态会不同于 OpenShift Machine Config 中的配置。这就是所谓的“配置漂移”。例如,集群管理员可能会手动修改一个 RHCOS 节点中的文件,例如一个 systemd 单元文件,或者 RHCOS 中一个通过 MachineConfig 配置的文件权限。这就差异就是配置漂移。配置漂移不但有可能产生安全隐患,还有可能在 MachineConfigPool 中的节点之间或 MachineConfig 更新时造成问题。
OpenShift 的 Machine Config Operator(MCO)使用 Machine Config Daemon(MCD)定期检查节点的配置漂移。MCD 在以下情况会执行配置漂移检测:
- 当一个节点启动时。
- 绕过 OpenShift Machine Config 机制对主机配置(Ignition 文件和 systemd 单元)进行修改后。
- 在应用新的 MachineConfig 之前。
在进行配置漂移检测时,MCD 会验证文件内容和权限是否与当前应用的 Machine Config 所规定的完全一致。如果 MCD 检测到了配置漂移,MCD会执行以下任务。
- 向控制台日志发出一个错误信息
- 发出一个 Kubernetes 事件
- 停止对节点的进一步检测
- 将节点和 Machine Config Pool 设置为 “Degraded”
如果检测到节点发生配置漂移,MCO 就会将节点和 Machine Config Pool(MCP)设置为 “Degraded” 降级状态并报告错误。被降级的节点虽然还处于在线可以运行状态,但是已经不能被更新。
形成配置漂移
- 查看当前针对 Worker 节点 MCP,当前 DEGRADEDMACHINECOUNT 数量为 “0”。
- 通过 debug 进入一个 Worker Node。
- 修改 /etc/mco/proxy.env 文件为以下内容。
- 用命令或在 OpenShift 控制台中再次查看 MCP (机器配置池)对象。可以看到名为 worker 的 MCP 已经处于 “DEGRADEDMACHINECOUNT (降级)” 状态了。

- 查看名为 worker 的 MCP,其中提示是哪个节点出现了配置漂移,以及配置漂移文件是 “/etc/mco/proxy.env”。
这条消息显示一个节点的 /etc/mco/proxy.env 文件是由 MachineConfig 添加的,但是在 MachineConfig 之外发生了变化。
- 查看上一步提示的出现配置漂移的节点,根据提示可知该节点的 "/etc/mco/proxy.env"和名为“rendered-worker-cacd3898ae540c0ceff38fefcc91a815”的 MachineConfig 冲突了。
处理配置漂移
可以通过执行以下任意补救措施来纠正配置漂移并将节点返回到 “Ready” 状态。
- 根据根据当前 OpenShift 的 MachineConfig 配置手动修改降级的节点的相关文件内容或改变文件权限。
- 在降级的节点上生成一个强制文件。强制文件使 MCD 绕过通常的配置漂移检测,重新应用当前的机器配置。
手工恢复配置
- 找到在上一步中名为 “machineconfiguration.openshift.io/desiredConfig” 注释内容 “rendered-worker-cacd3898ae540c0ceff38fefcc91a815”,然后查看这个 MachineConfig 中的 “proxy.env” 内容。
- 将上一步 “data:,” 后面的内容(这部分内容被 URL 编码了)复制到 “https://www.urldecoder.net/” 网页中,在DECODE后可以看到 “proxy.env” 文件的原始信息。
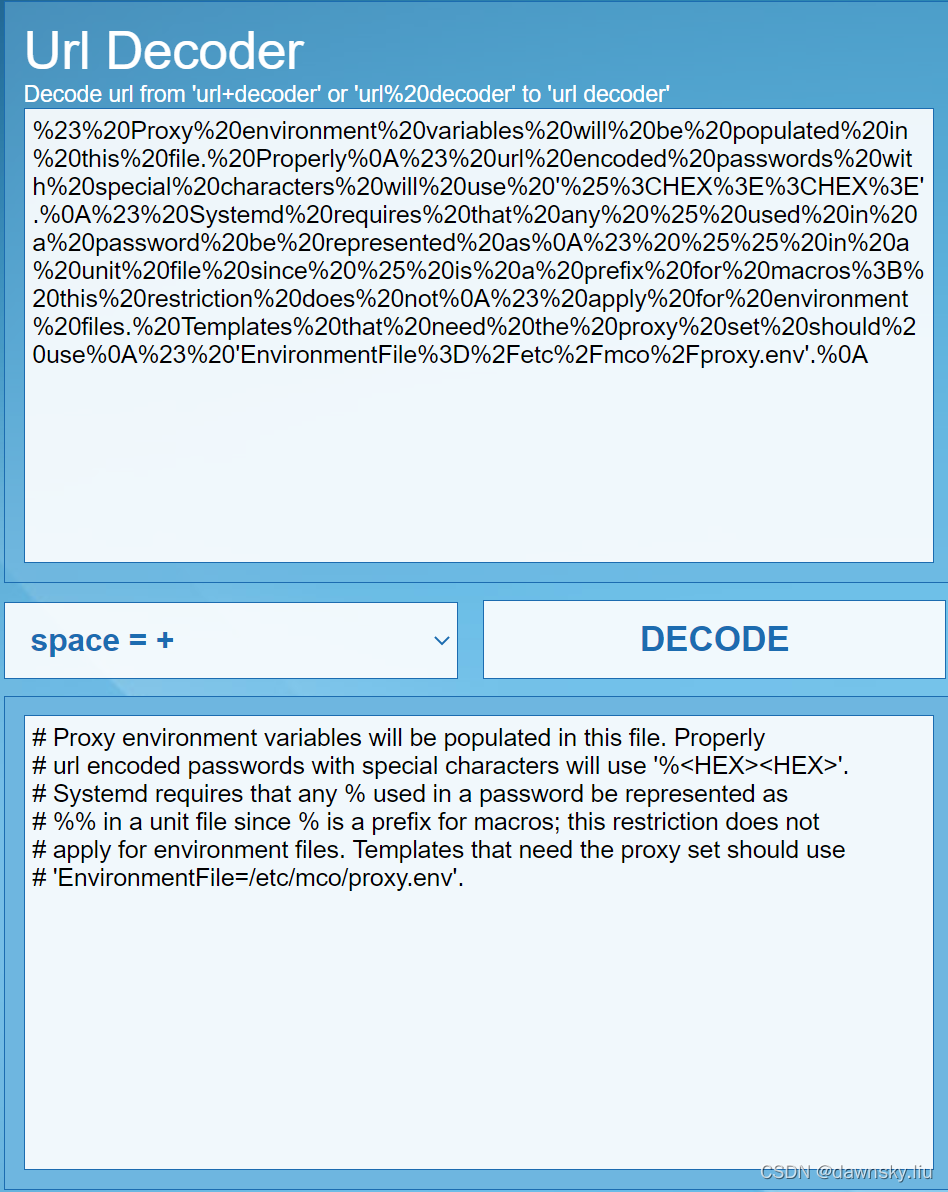
或者执行以下命令,显示上面的 “data:,” 后面的内容。
- 可以进提示有配置漂移的 Node 中,再根据上面获得原始文件内容修改 /etc/mco/proxy.env 文件。
强制恢复配置
- 使用前面说明的 “oc debug” 命令再次进入出现配置漂移的 Node,然后执行以下命令即可强制恢复漂移配置。
- 执行上面命令后先退出 Node,然后再执行以下命令,确认最终 DEGRADEDMACHINECOUNT 又恢复 “0” 了。
参考
https://access.redhat.com/solutions/5414371