
这项工作采用的技术是在单独的视窗环境中创造烟火,如果需要将 hdfs 连接到虚拟机器,程序如下:
I. 窗口的环境配置
1、java的安装
以下是一个建议:使用下版的爪哇, 如果对上版有问题, 在我的早期文章中, Java 和 Hadoop 的安装程序有问题, 你可以读到。
hadoop安装
2. 哈多布的安装
hadoop安装
链接同上
3. Scala安装
Scala的拉链包首先下载 并保留官方网站 推荐的2.Verion 11, 因为之后我们使用的火花版本是 2. Four. 3。
都是为了解除压缩包的压缩
为了能够进行后续跟踪,建议所有不压力文件都存储在同一目录中。
配置环境变量, SCALA_ HOME, 降压后路径 。
4. 火烧装置
当然,如果你鄙视看到很多红日志数据
您可以在公园的子目录中再次编辑 log4j 文件 。
插入对数 4j. rootCategory 并设置 Error 选项 。
大多数日志信息将被隐藏 。
在你不再承受压力之后 也是组合环境变数
最终,试验被认为是成功的。
java -version
hadoop version
spark-shell
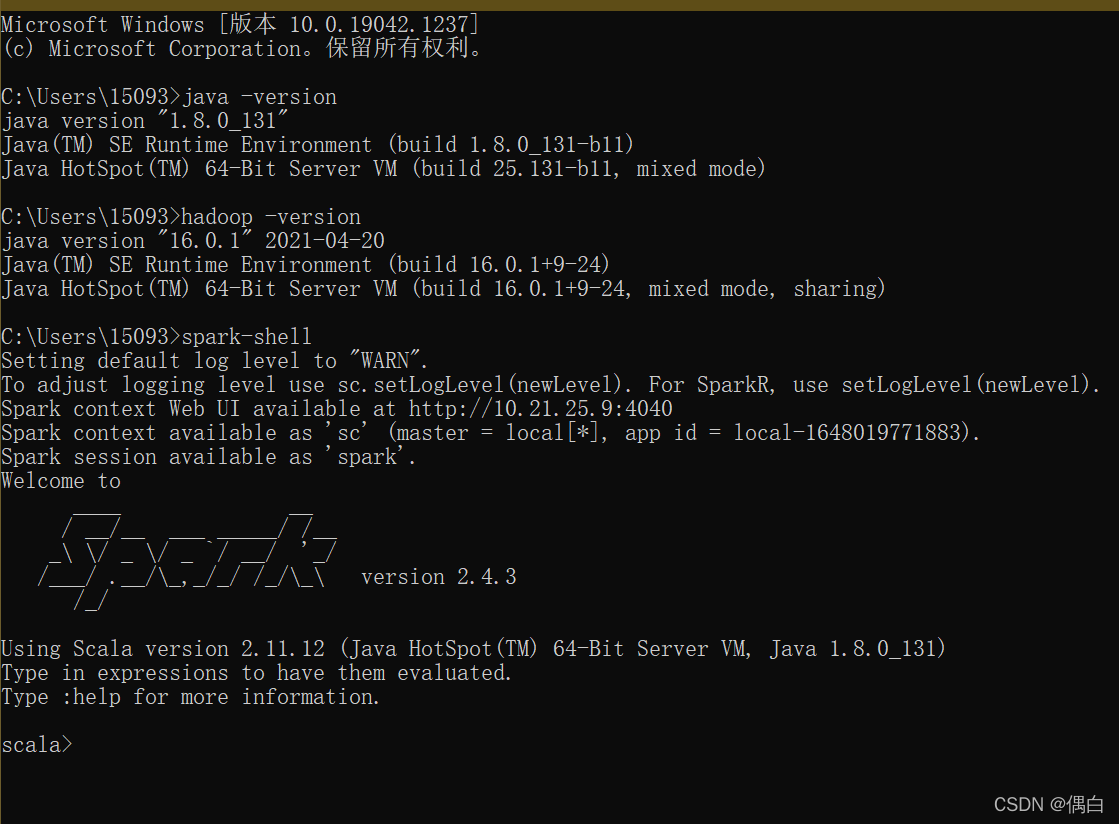
这就是生态系统是如何建立的。
二. 烟火的进口
先装好Pyspark
第一步是下载矿坑,然后用pip安装。
* 确保在使用 SPARK_HOME 环境变量之前先设置该变量*
有两种方法 开始与皮斯帕克。
方法一:命令行启动
与 Sark 连接并输入命令行中的以下指令, 以便您在 jupyter 中直接更改环境变量 。
此方法可以输入到命令行, 并且 sc 对象已经构建, 所以不需要再导入 。
FHPSPARK用于方法二。
输入一条无意义的消息:“ Pip 安装查找点” 是第一个命令 。
因此,在开始创建代码之前, 请在下面输入两个语句 。
*实例代码*
*常见报错解决*
第一,如果无法找到公园。 Init () 被错误地报告 。
然后,在大多数情况下,没有SPARK_HOME环境设置;记得正确的设置。
2、Py4JError:org.apache.spark.api.python.PythonUtils.isEncryptionEnabled does not exist in the JVM
我早就有这个问题了如果jdk、火花和Hadop配置得当(正确的设置假设从指挥线可以发射 sark-shell ), 那么 sark-shell 就可以启动 。因此,问题在于Python版本。我的答案是把俾斯公园恢复到2.3.2版本
一次输入以下命令 。
pip uninstall pyspark
pip install pyspark==2.3.2
3、pyspark.sql.utils.IllegalArgumentException: 'Unsupported class file major version 565760
JDK版本的原因
你可以先看相对论版本。

修改系统的 Java 版本( 最小版本), 并记住环境变量以更新设置 。
所以我们才在这里,八点零13分,没有问题。确保环境变量更新。确认你准确无误。
ok,可以了