
来源: https://ww.cnblogs.com/jiangxueqiao/p/7464408.html
连结到字符编码雾系列文章:
- dial-in字符编码的雾 - 字符编码的描述
- dial-in字符编码的雾 -编译器如何处理文件编码
- dial-in字符编码的雾 - 字符编码转换
- dial-in字符编码的雾--MySQL数据库字符编码
1.Visual Studio字符集
使用Visual Studio创建的C++项目可以具有项目属性配置属性-->常规中配置字符集:使用Unicode字符集(默认)、使用多字节字符集。
如图:
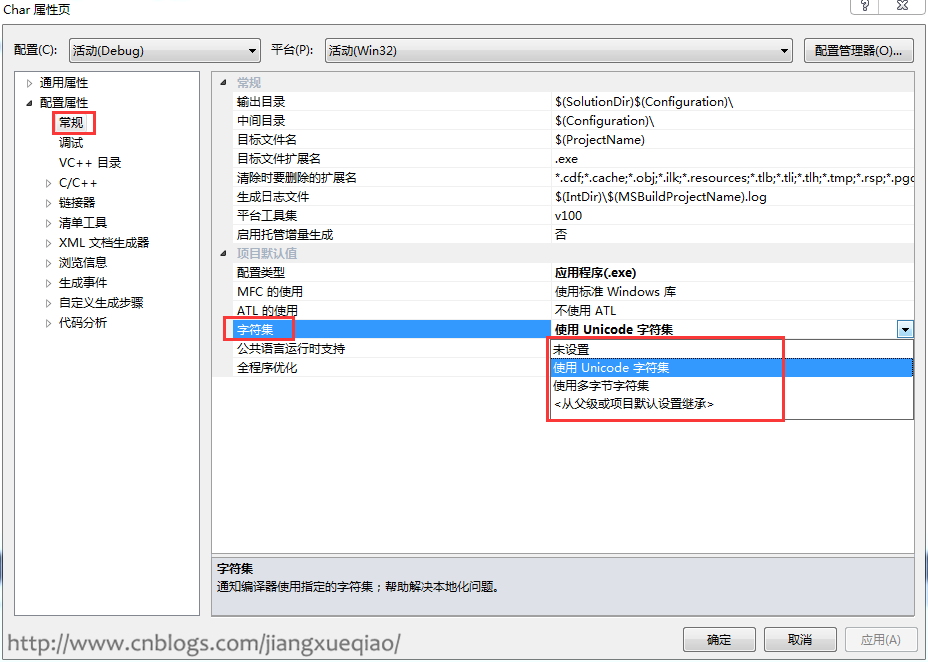
但此设置不会对编译器处理字符编码产生直接影响(请注意“直接”字在这里,第3节提到),仅在工程属性中配置属性-->C/C++-->预处理器加入相应的宏:
这些宏通常用于确定是否使用字符串或图形t,它在系统API中更广泛地使用,如果消息框通过定义UNICODE宏来确定是否使用LPCSTR或LPCWSTR(const char), LPCWSTR 序列图):
2.字符和图
如上所述,在定义API时,必须确定UNICODE宏是否定义为使用图形或图形_t,那么图形和图形_t之间的区别是什么?
char和wchar_t是标准C/C++字型,它不是单一的窗口。固定字符是一个字节,wchart为2个字符固定,从内存的角度来看,例如字符、图形和其它数据类型,只是代表记忆的一部分,用于存储固定长度的二进制0或1。 在编程时,我们通常习惯于存储字符串在字符串或图表t定义的内存空间中,将格式存储在因特定义的内存空间中。
因此, char 或 chart_t 被用于存储字符,这些字符只是在内存分配和数据存储上的事情,它们本身并不直接与字符编码有关(参见这里“直接”字段,第3节)。
3.编译器如何处理硬编码字符
在VC++编译器源代码处理步骤中,处理有两个主要步骤:
第1步:预处理
1.1)阅读源文件,确定源文件中使用的字符编码类型。
不了解字符编码的朋友可以参考前一篇博客 dial-in字符编码的雾 - 字符编码的描述
1.2)转换源文件的内容源字符集(Source Character Set), Moore考虑UTF-8代码。
第2步:链接
2.1)将1.UTF-8转换为2执行字符集(Execution Character Set):
- 用于宽弦(即宽弦)。
L标记的串,如L"abc",L'中'),执行字符集编码为UTF-16。 - 对窄字符串(和相应的宽字符串,即.
L标记的串),执行字符集系统当前代码页。

现在我们可以说,Visual Studio字符集设置、字符、图形和图形t间接影响了编译器处理字符编码的方式:
Visual Studio 2010之后的支援(包括)
# pragma execution_character_set来设置执行字符集。
4. 实例分析
- 已知的“中国”字的多种代码如下:
- 函数
DumpCharacterCode以内存字节打印数据:
如何设置系统代码页:
“控制面板” --> “区域和语言” --> “管理” --> “非Unicode程序的语言” --> “更改系统区域设置”Visual Studio将文件保存到指定的编码方法:
“文件” --> “高级保存选项”
4.1测试编译器处理窄字符编码
测试代码如下:
对于不同的系统代码页和源文件编码,印制的中文字符的“in”编码是:
| 测试用例 | 系统代码页 | 保存源文件编码 | 编译器用来判断文件的代码 | 源字符集 | 执行字符集 | 打印输出 |
|---|---|---|---|---|---|---|
| 用例1 | 简化中文CP936 | 简化中文CP936 | 简化中文CP936 | UTF-8 | 简化中文CP936 | D6 D0 |
| 用例2 | 简化中文CP936 | UTF-8 BOM | UTF-8 | UTF-8 | 简化中文CP936 | D6 D0 |
| 用例3 | 简化中文CP936 | UTF-8 | 简化中文CP936 | UTF-8 | 简化中文CP936 | 编译错误(C2146) |
| 用例4 | 西欧 CP1252 | 简化中文CP936 | 西欧 CP1252 | UTF-8 | 西欧 CP1252 | D6 D0 |
| 用例5 | 西欧 CP1252 | UTF-8 BOM | UTF-8 BOM | UTF-8 | 西欧 CP1252 | 3F 00 |
下面的步骤在表4至6中列出。
3F相应的ASCII字符是?当编译器遇到不可识别的字符时,它使用?来替代。 出现?这种情况将伴随翻译警告C4566。
上面出现了1次3F(例5),误spelling的原因是UTF-8 --> 西欧 CP1252.西欧 CP1252这是ASCII扩展,它不支持中文字符,所以使用3F替代。
为什么在第3例中有一个翻译错误?
微软的编译器只能用BOM识别UTF-8,例如没有BOM的UTF-8,编译器将确定源文件编码为系统当前代码页CP936。E4 B8 AD,在CP936到UTF-8转换后执行5列E6 B6 93 3F,列6再要将E6 B6 93 3F转换为CP936肯定是转换不回去的,相当于 UTF-8(1) --> UTF-8 (2),再将UTF-8(2)转换回CP936,这时肯定得到的字符不是原来的字符了。
用例4为什么输出的D6 D0,而不是3F?
请看例4的用途顺序,源文件通过CP936保存,但是编译器通过CP1252读取,CP1252是一个ASCII扩展,单字节的,尽管此时显示为随机代码,但字符仍然是D6D0;然后读取文件的内容由CP1252转换为UTF-8编码,在编码到C396C390之后,再编码到CP1251的UTF-8编码,之后代码被转换为D6D0。 但这个D6 D0如果添加例4,在CP1252中无法显示MessageBoxA(NULL,"middle","test",MB_OK);你会发现,在弹出对话框中的显示仍然是 wildcard。
可以使用下面的代码进行测试(ANSIToUTF8、UTF8ToANSI函数见
dial-in字符编码的雾 - 字符编码转换
):
4.2测试编译器处理宽字符编码
测试代码如下:
同样,对于不同的系统代码页和源文件编码,印制的中文字符的“in”编码是:
| 测试用例 | 系统代码页 | 保存源文件编码 | 编译器用来判断文件的代码 | 源字符集 | 执行字符集 | 打印输出 |
|---|---|---|---|---|---|---|
| 用例1 | 简化中文CP936 | 简化中文CP936 | 简化中文CP936 | UTF-8 | UTF-16 | 2D 4E 00 00 |
| 用例2 | 简化中文CP936 | UTF-8 BOM | UTF-8 | UTF-8 | UTF-16 | 2D 4E 00 00 |
| 用例3 | 简化中文CP936 | UTF-8 | 简化中文CP936 | UTF-8 | UTF-16 | 编译错误(C2146) |
| 用例4 | 西欧 CP1252 | 简化中文CP936 | 西欧 CP1252 | UTF-8 | UTF-16 | D6 00 D0 00 尺寸末端 |
| 用例5 | 西欧 CP1252 | UTF-8 BOM | UTF-8 BOM | UTF-8 | UTF-16 | 2D 4E 00 00 |
5.完全避免硬编码字符扭曲
从第3节很容易知道,为了开发在任何语言(系统代码页)窗口环境中通常编译的多语言程序,并且没有随机代码运行,必须遵循下列原则:
- 代码文件是UTF-8,有BOM编码。
- Visual Studio字符集设置为Unicode字符集。
- 使用 chart_t。
为了完成上述三个步骤,你的代码将由其他人从 jithub中克隆下来,而不是因为你的代码包含中文字符或类似的东西error C2015这样的编译错误不会导致错误拼写的代码.
本文提出的方法仅用于解决硬编码字符解码问题,至于数据传输中的解码问题,需要统一字符编码来解决。
管理微软C/C++编译器中的字符集的新选项 - C++ Team Blog