
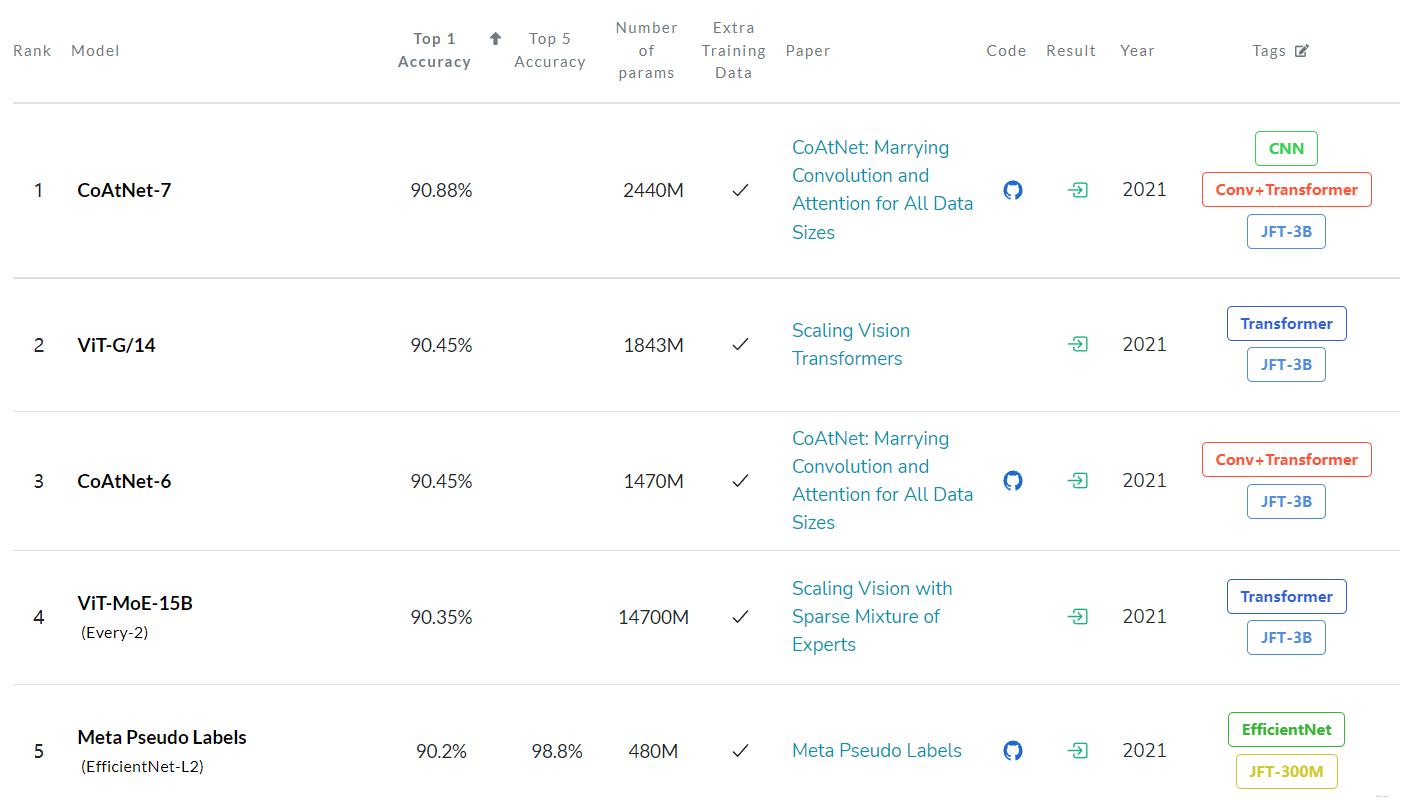
CoAt = Evolution 的邮件组件无法初始化 。本页是我们对2011年马来西亚选举的特别报道的一部分。将体积与变形器结合起来,在业绩方面取得了突破。这一技术打算在若干方面是非常规的。模型的结构经过仔细研究。
引言
变压器模型的容量很大,但由于缺乏适当的汇总偏差,其一般化能力小于量网络的能力。
建议使用CoAtNet示范组:
- 能够将体积和自我注意分离开来,可以使用简单的相对注意来协调它们。
- 曲线和关注层的超级混合对一般化能力和效率产生了巨大影响。
方法
本节重点介绍将conv和变压器组合在一起的最佳技术:
- 如果在基本计算区块中,体积与自我观察相配合。
- 如何组织几个计算机单位组成整个网络。
合并卷积与自注意力
卷中的谷歌使用传统的MBConv,用深度将体积分开,以捕捉空间之间的相互作用。
卷积操作的表示: L ( i ) mathcal{L}(i) L ( i ) 代表周围地区,即排量处理的感觉。
y i = ∑ j ∈ L ( i ) w i − j ⊙ x j (depthwise convolution) y_{i}=sum_{j in mathcal{L}(i)} w_{i-j} odot x_{j} quad text { (depthwise convolution) } y i = j ∈ L ( i ) ∑ w i − j ⊙ x j (depthwise convolution)
自注意力表示: G mathcal{G} G 这个故事是我们全球空间感觉狂野特别报导的一部分。
y i = ∑ j ∈ G exp ( x i ⊤ x j ) ∑ k ∈ G exp ( x i ⊤ x k ) ⏟ A i , j x j (self-attention) y_{i}=sum_{j in mathcal{G}} underbrace{frac{exp left(x_{i}^{top} x_{j}right)}{sum_{k in mathcal{G}} exp left(x_{i}^{top} x_{k}right)}}_{A_{i, j}} x_{j} quad text { (self-attention) } y i = j ∈ G ∑ A i , j ∑ k ∈ G exp ( x i ⊤ x k ) exp ( x i ⊤ x j ) x j (self-attention)
一体化技术一:第一,宁静,然后软式
y i post = ∑ j ∈ G ( exp ( x i ⊤ x j ) ∑ k ∈ G exp ( x i ⊤ x k ) + w i − j ) x j y_{i}^{text {post }}=sum_{j in mathcal{G}}left(frac{exp left(x_{i}^{top} x_{j}right)}{sum_{k in mathcal{G}} exp left(x_{i}^{top} x_{k}right)}+w_{i-j}right) x_{j} y i post = j ∈ G ∑ ( ∑ k ∈ G exp ( x i ⊤ x k ) exp ( x i ⊤ x j ) + w i − j ) x j
一体化技术二:先是软性,然后是和平
y i pre = ∑ j ∈ G exp ( x i ⊤ x j + w i − j ) ∑ k ∈ G exp ( x i ⊤ x k + w i − k ) x j y_{i}^{text {pre }}=sum_{j in mathcal{G}} frac{exp left(x_{i}^{top} x_{j}+w_{i-j}right)}{sum_{k in mathcal{G}} exp left(x_{i}^{top} x_{k}+w_{i-k}right)} x_{j} y i pre = j ∈ G ∑ ∑ k ∈ G exp ( x i ⊤ x k + w i − k ) exp ( x i ⊤ x j + w i − j ) x j
这项研究寻求在参数和计算两方面采用第二种综合方法。
垂直布局设计
在选择如何将量与重点结合起来时,有必要探索如何构建网络的总体结构,同时考虑以下三个主要因素:
- 为了最大限度地减少空间的尺寸,采用降压样本,然后采用全球相对技术。
- 在某种程度上,地方注意力被用来推动全球感知领域。
- Scaling local self-attention for parameter efficient visual backbone
- Swin Transformer
- 应当使用线性技术,而不是二次软性注意。
- Efficient Attention
- Transformers are rnns
- Rethinking attention with performers
由于第二种技术效率低下,第三种方法无效,因此采用第一种方法构建样本模式有多种替代办法:
- 与步数抽样匹配的音量
- 利用集合程序,完成下降样本,建立多阶段网络模式。
- 根据第一种方案提出 V i T R E L ViT_{REL} V i T R E L ,即使用 Vit Stem 直接堆叠 L层变形器块,同时使用活性附件。
- 多阶段软件用于在第二种选择中提供示范组: S 0 , . . . , S 4 S_0,...,S_4 S 0 , . . . , S 4 ,如下图所示:
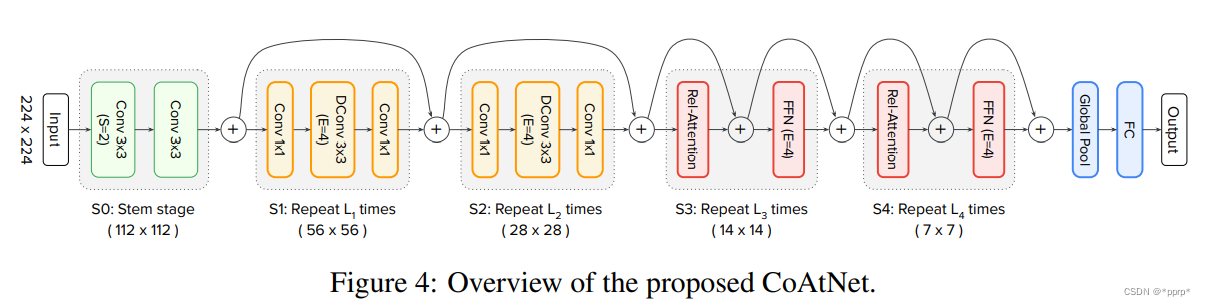
S o − S 2 S_o-S_2 S o − S 2 使用量和命令行的 MBConv 。 S 2 − S 4 S_2-S_4 S 2 − S 4 许多模块都使用变换器结构。变换器内部有几种变异:C为体积,T为变换器。
- C-C-C-C
- C-C-C-T
- C-C-T-T
- C-T-T-T
第一个测试模型的普及能力
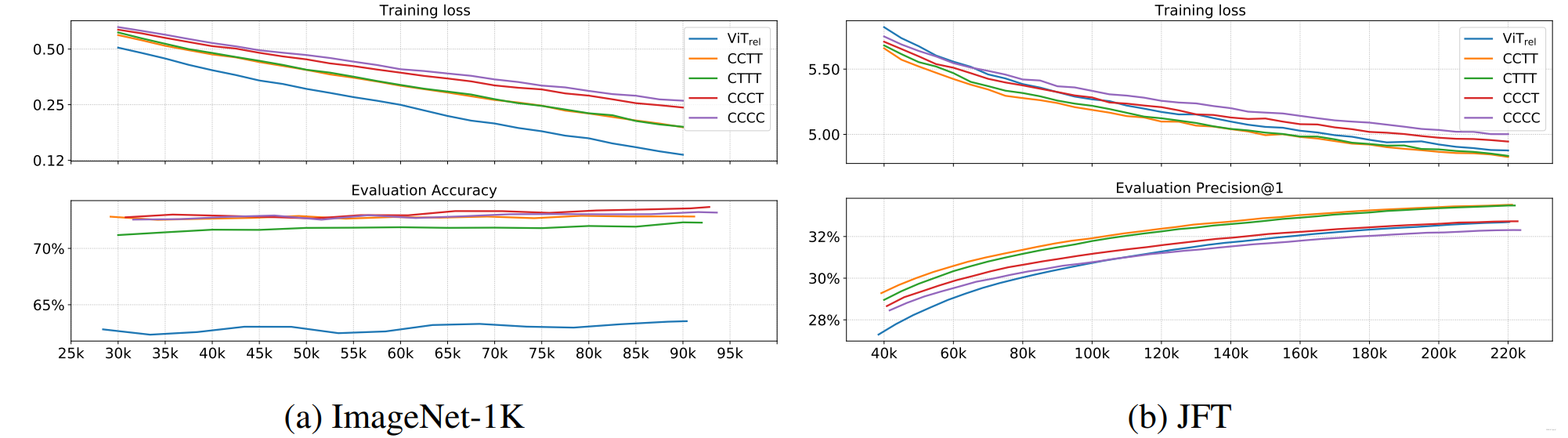
普遍化安排如下:(证明结构中的数量作业仍须按比例进行)
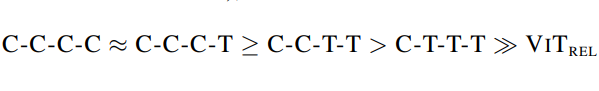
初步测试模型容量
分类结果主要取决于JFT和图像网络-1k的不同性能,分类结果如下:
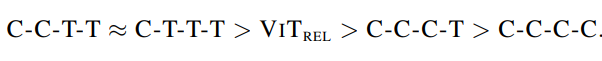
测试模型迁移能力
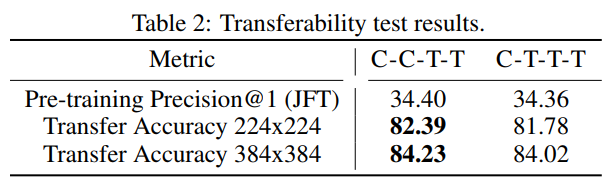
进行了一次移民能力测试,以进一步比较CCTT与CTT, 并且确定CCT能够超过CTT。
最终CCTT胜出!
实验
与SOTA模型的结果相比:
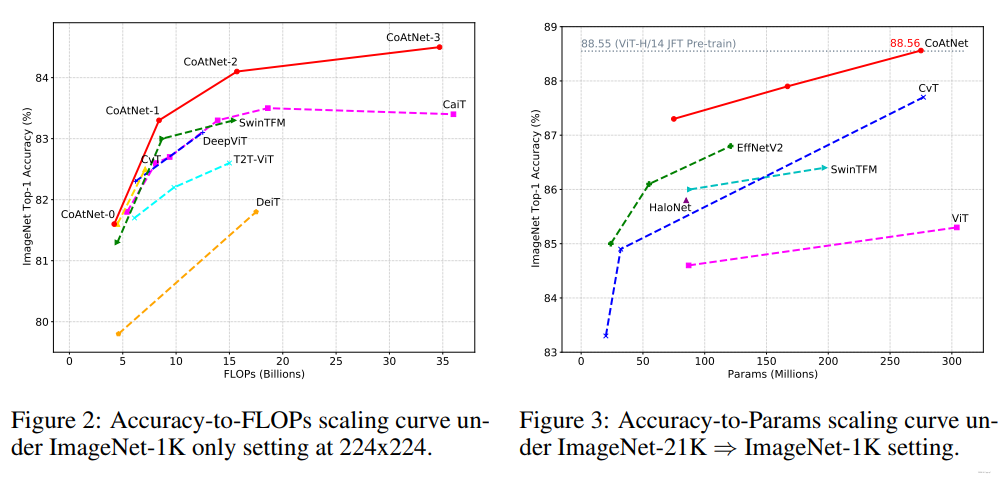
实验结果:
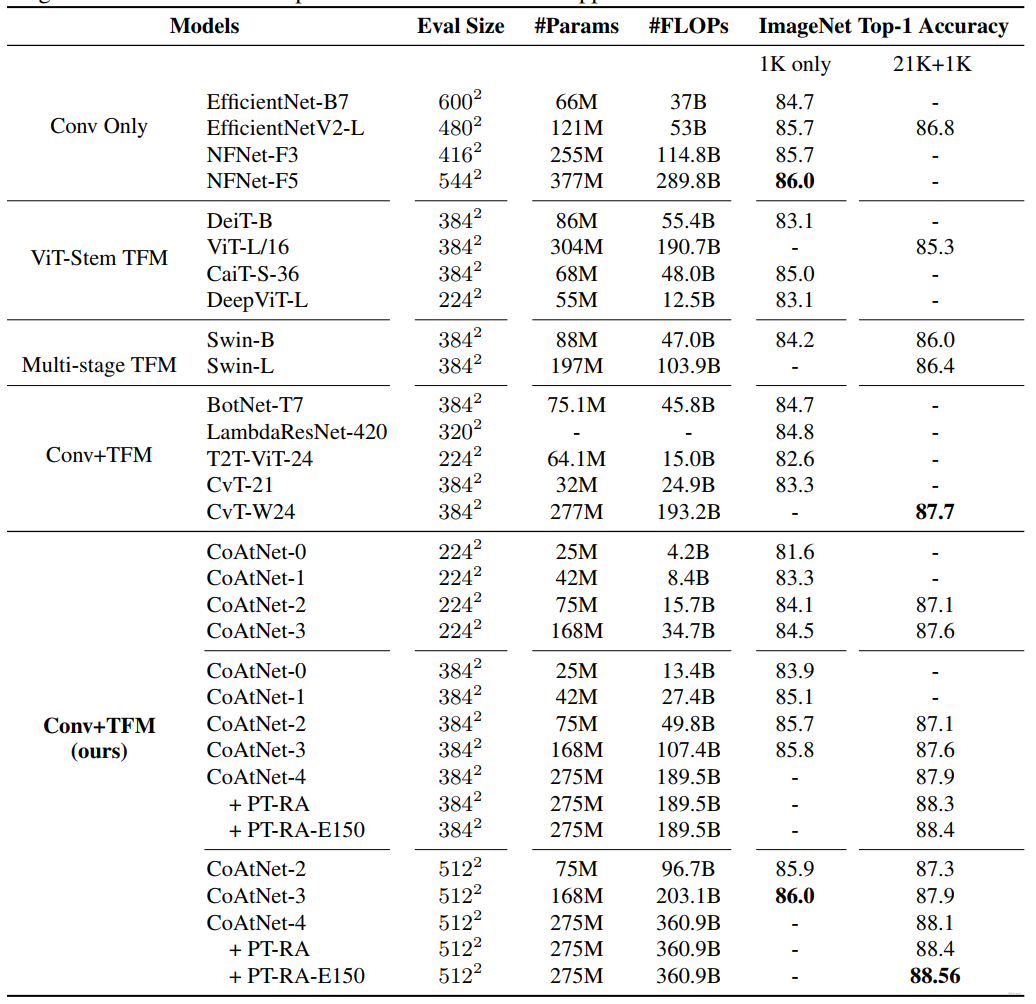
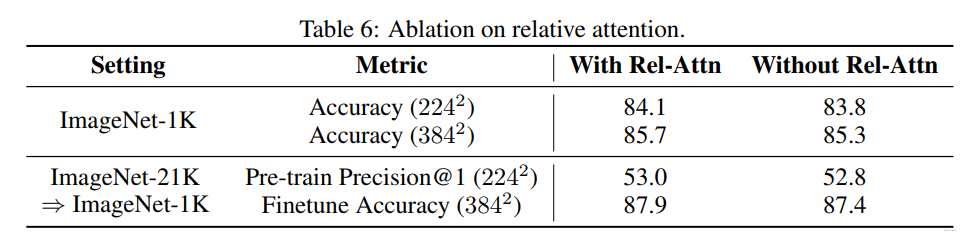
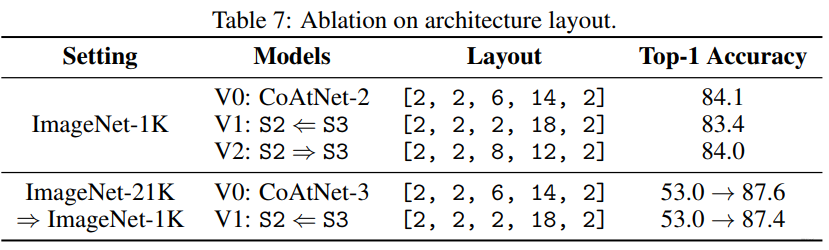
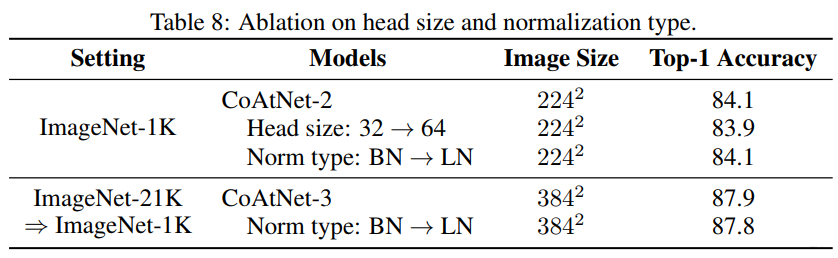
消融实验:
代码
在浅层,MBConv模块如下:
最关心的是关注区块设计,Reality position:
参考
https://arxiv.org/pdf/2106.04803.pdf
https://github.com/chinhsuanwu/coatnet-pytorch