
1 回顾 :DQN
国家行动价值行动(Q-功能)_UQI-LIWJ 博客-CDN DQN
DQN是希望通过神经网络向Q(s,a)学习的结果。我们进入一个人的状态,DQN为每个动作返回匹配的Q(s,a)。
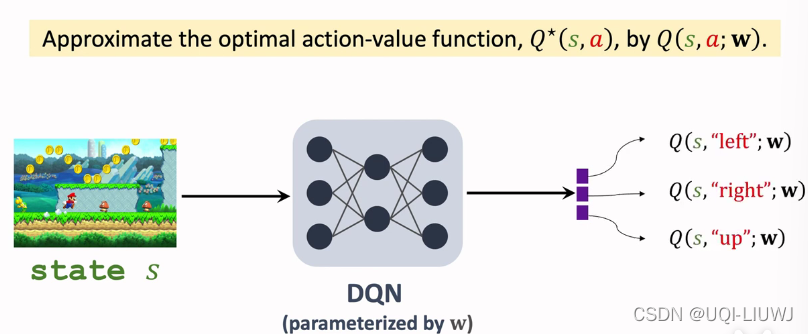
TD公司通常用于解决DQN。
例如,问题(s,a)是真正参与的真正报酬。
给预报给定了值函数。
(由于Q是一个跨目标网络, qt和yt将略有不同 。)
我们每次在DQN做样本时 我们讨论过, 我们得到一套线条。
,然后使用这个子集来计算相应的损失并将梯度向下调整。
在对模型进行培训后,数据集被删除。


2 TD算法的缺点
2.1 缺乏经验

事实上,经验可以重复。
2.2 correlated updates
例如,在玩游戏时,当前图象与下一个图象的差别相对微小。 研究表明尽可能传播这种阴极数据 有利于改进训练
研究表明尽可能传播这种阴极数据 有利于改进训练

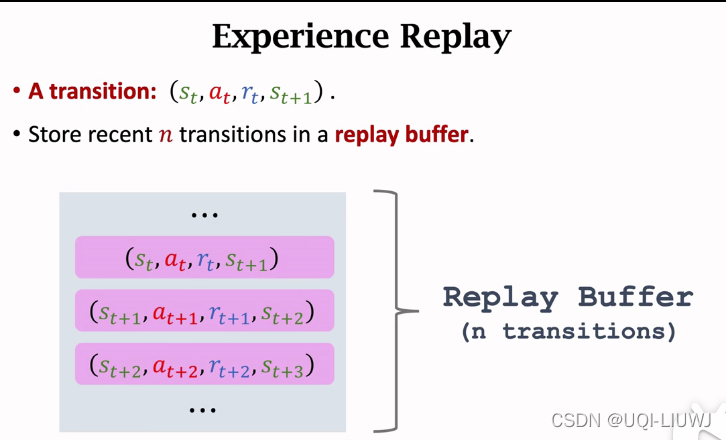
3 经验回放
上述两个弱点可以通过经验审查来解决。
以最接近的n-record 填充缓冲 。
如果你填满它,每次插入一个新的,就删除世界上最古老的项目。
三.1 利用经验支持的TD

这是从缓冲中随机选择种子, 实际上是从缓冲中随机选择批量, 成为小型批量 SGD 。
3.2 经验回顾的优点
1 排除了转换的意义
2 重复使用经验
4 优先经验回放
缓冲系统包含一些转让,每个转让都有不同的优先级。
将超级玛丽视为左方的标准水平和右方的老板水平。 考虑到右方经验有限,不可能真正了解如何在非右方情景下做出判断,在这种情况下,右方更为重要。

在开源器的实验性重播中,如果某一项的TD误差水平较高,据说TD误差水平较高。因此,我们认为他比TD目标还大。DQN对这种情况并不熟悉。因此,应当给予他更优先的地位。
采用两种抽样方法,一流的教训用不平等的抽样取代了偶数的抽样,取而代之的是两种抽样方法。
等级(t) 是 Plat 的序列号。 级别( t) 越大, 级别( t) 越低 。

由于抽样不统一,我们必须修改学习率,以减少不同抽样概率的差异。
如果交易的采样概率较高,他的学习率应适当降低(以抵消与高采样概率的差异,这将导致我被采样的次数略多一点)。


如果只是收集一个项目,而我们却不知道,我们就给他最高优先级别,即未使用的优先级别。
我们每次利用它时 都会更新所有东西

参考资料:
更多的内部学习(全部)